Fighting for a human future.
AI is poised to remake the world.
Help us ensure it benefits all of us.
Help us ensure it benefits all of us.
Recent updates from us
Including: Anthropic's new Claude Mythos model; Trump endorses an AI kill switch; Florida opens the first criminal probe of an AI company; and more.
1 May, 2026
Including: AI vs. Cancer; proposed data center moratorium; military AI news; and more.
1 April, 2026
Including: Anthropic drama; our new Protect What's Human campaign; war game simulations show AI defaults to terrifying outcomes; and more.
1 March, 2026
Hear from us every month
Join 70,000+ other newsletter subscribers for monthly updates on the work we’re doing to safeguard our shared futures.
Our Mission
Steering transformative
technology towards benefiting life and away from extreme large-scale risks.
technology towards benefiting life and away from extreme large-scale risks.
We believe that the way powerful technology is developed and used will be the most important factor in determining the prospects for the future of life. This is why we have made it our mission to ensure that technology continues to improve those prospects.
Learn more
Focus Areas

Artificial Intelligence
AI can be an incredible tool that solves real problems and accelerates human flourishing, or a runaway uncontrollable force which destabilizes society, disempowers most people, enables terrorism, and replaces us.

Biotechnology
Advances in biotechnology can revolutionize medicine, manufacturing, and agriculture, but without proper safeguards, they also raise the risk of engineered pandemics and novel biological weapons.

Nuclear Weapons
Peaceful use of nuclear technology can help power a sustainable future, but nuclear weapons risk mass catastrophe, escalation of conflict, the potential for nuclear winter, global famine and state collapse.
Featured videos
The best recent content from us and our partners:
More videos
Featured projects
Read about some of our current featured projects:
Recently announced

The Pro-Human AI Declaration
A remarkable bipartisan coalition of leading organizations and prominent figures have announced their support for a set of Pro-Human principles to guide our shared future with AI.
Policy & Research
View all

Promoting a Global AI Agreement
We need international coordination so that AI's benefits reach across the globe, not just concentrate in a few places. The risks of advanced AI won't stay within borders, but will spread globally and affect everyone. We should work towards an international governance framework that prevents the concentration of benefits in a few places and mitigates global risks of advanced AI.

Recommendations for the U.S. AI Action Plan
The Future of Life Institute proposal for President Trump’s AI Action Plan. Our recommendations aim to protect the presidency from AI loss-of-control, promote the development of AI systems free from ideological or social agendas, protect American workers from job loss and replacement, and more.

AI Convergence: Risks at the Intersection of AI and Nuclear, Biological and Cyber Threats
The dual-use nature of AI systems can amplify the dual-use nature of other technologies—this is known as AI convergence. We provide policy expertise to policymakers in the United States in three key convergence areas: biological, nuclear, and cyber.
Promoting a Global AI Agreement
We need international coordination so that AI's benefits reach across the globe, not just concentrate in a few places. The risks of advanced AI won't stay within borders, but will spread globally and affect everyone. We should work towards an international governance framework that prevents the concentration of benefits in a few places and mitigates global risks of advanced AI.
Recommendations for the U.S. AI Action Plan
The Future of Life Institute proposal for President Trump’s AI Action Plan. Our recommendations aim to protect the presidency from AI loss-of-control, promote the development of AI systems free from ideological or social agendas, protect American workers from job loss and replacement, and more.
AI Convergence: Risks at the Intersection of AI and Nuclear, Biological and Cyber Threats
The dual-use nature of AI systems can amplify the dual-use nature of other technologies—this is known as AI convergence. We provide policy expertise to policymakers in the United States in three key convergence areas: biological, nuclear, and cyber.
Futures
View all

AI’s Role in Reshaping Power Distribution
Advanced AI systems are set to reshape the economy and power structures in society. They offer enormous potential for progress and innovation, but also pose risks of concentrated control, unprecedented inequality, and disempowerment. To ensure AI serves the public good, we must build resilient institutions, competitive markets, and systems that widely share the benefits.

Envisioning Positive Futures with Technology
Storytelling has a significant impact on informing people's beliefs and ideas about humanity's potential future with technology. While there are many narratives warning of dystopia, positive visions of the future are in short supply. We seek to incentivize the creation of plausible, aspirational, hopeful visions of a future we want to steer towards.

Perspectives of Traditional Religions on Positive AI Futures
Most of the global population participates in a traditional religion. Yet the perspectives of these religions are largely absent from strategic AI discussions. This initiative aims to support religious groups to voice their faith-specific concerns and hopes for a world with AI, and work with them to resist the harms and realise the benefits.
AI’s Role in Reshaping Power Distribution
Advanced AI systems are set to reshape the economy and power structures in society. They offer enormous potential for progress and innovation, but also pose risks of concentrated control, unprecedented inequality, and disempowerment. To ensure AI serves the public good, we must build resilient institutions, competitive markets, and systems that widely share the benefits.
Envisioning Positive Futures with Technology
Storytelling has a significant impact on informing people's beliefs and ideas about humanity's potential future with technology. While there are many narratives warning of dystopia, positive visions of the future are in short supply. We seek to incentivize the creation of plausible, aspirational, hopeful visions of a future we want to steer towards.
Perspectives of Traditional Religions on Positive AI Futures
Most of the global population participates in a traditional religion. Yet the perspectives of these religions are largely absent from strategic AI discussions. This initiative aims to support religious groups to voice their faith-specific concerns and hopes for a world with AI, and work with them to resist the harms and realise the benefits.
Communications
View all

Protect What’s Human
We’re building a pro-human movement for commonsense regulation to keep AI safe and under our control, kicking off with a national ad campaign airing in the US.

Control Inversion
Why the superintelligent AI agents we are racing to create would absorb power, not grant it | The latest study from Anthony Aguirre.

Digital Media Accelerator
The Digital Media Accelerator supports digital content from creators raising awareness and understanding about ongoing AI developments and issues.
Protect What’s Human
We’re building a pro-human movement for commonsense regulation to keep AI safe and under our control, kicking off with a national ad campaign airing in the US.
Control Inversion
Why the superintelligent AI agents we are racing to create would absorb power, not grant it | The latest study from Anthony Aguirre.
Digital Media Accelerator
The Digital Media Accelerator supports digital content from creators raising awareness and understanding about ongoing AI developments and issues.
Grantmaking
View all

AI Existential Safety Community
A community dedicated to ensuring AI is developed safely, including both faculty and AI researchers. Members are invited to attend meetings, participate in an online community, and apply for travel support.

Fellowships
Since 2021 we have offered PhD and Postdoctoral fellowships in Technical AI Existential Safety. In 2024, we launched a PhD fellowship in US-China AI Governance.

RFPs, Contests, and Collaborations
Requests for Proposals (RFPs), public contests, and collaborative grants in direct support of FLI internal projects and initiatives.
AI Existential Safety Community
A community dedicated to ensuring AI is developed safely, including both faculty and AI researchers. Members are invited to attend meetings, participate in an online community, and apply for travel support.
Fellowships
Since 2021 we have offered PhD and Postdoctoral fellowships in Technical AI Existential Safety. In 2024, we launched a PhD fellowship in US-China AI Governance.
RFPs, Contests, and Collaborations
Requests for Proposals (RFPs), public contests, and collaborative grants in direct support of FLI internal projects and initiatives.
Newsletter
Regular updates about the technologies shaping our world
Every month, we bring 70,000+ subscribers the latest news on how emerging technologies are transforming our world. It includes a summary of major developments in our focus areas, and key updates on the work we do.
Subscribe to our newsletter to receive these highlights at the end of each month.
Recent editions
Including: Anthropic's new Claude Mythos model; Trump endorses an AI kill switch; Florida opens the first criminal probe of an AI company; and more.
1 May, 2026
Including: AI vs. Cancer; proposed data center moratorium; military AI news; and more.
1 April, 2026
Including: Anthropic drama; our new Protect What's Human campaign; war game simulations show AI defaults to terrifying outcomes; and more.
1 March, 2026
Including: Davos 2026 highlights (and disappointments); ChatGPT ads; Doomsday Clock update; Trump voters want AI regulation; and more.
2 February, 2026
View all
Latest content
The most recent content we have published:

Featured content
How AI Can, and Can't, Cure Cancer
A new essay by Emilia Javorsky, MD, MPH, Director of the Futures Program
Tech executives have promised that AI will cure cancer. The reality is more complicated — and more hopeful. This essay examines where AI genuinely accelerates cancer research, where the promises fall short, and what researchers, policymakers, and funders need to do next.
Read the essay ->Posts

FLI’s President and CEO on Trump’s support for an AI ‘kill switch’
President Trump said during an interview aired yesterday by Fox Business that “there should be” when asked if AI needs […]
16 April, 2026
FLI CEO’s statement on the attack against Sam Altman’s home
Anthony Aguirre, President and CEO of the Future of Life Institute, issued the following statement in response to the attack […]
10 April, 2026
Prominent Scientists, Faith Leaders, Policymakers and Artists Call for a Prohibition on Superintelligence, as Poll Shows Americans Don’t Want It
Initial signatories include AI pioneers Yoshua Bengio and Geoffrey Hinton, leading media voices Steve Bannon and Glenn Beck, Obama's National Security Advisor Susan Rice, business trailblazers Steve Wozniak and Richard Branson, five Nobel Laureates, former Irish President Mary Robinson, actors Stephen Fry and Joseph Gordon-Levitt, and hundreds of others.
27 March, 2026
Statement: Head of US Policy on the White House AI legislative recommendations
The White House published it’s long-awaited AI legislative recommendations on Friday, and it still includes a call for Congress to […]
22 March, 2026
View all
Podcasts
Available on all podcast platforms:

11 May, 2026
Papers



Use your voice
Protect what's human.
Big Tech is racing to build increasingly powerful and uncontrollable AI systems designed to replace humans. You have the power to do something about it.
Take action today to protect our future:
Take Action ->
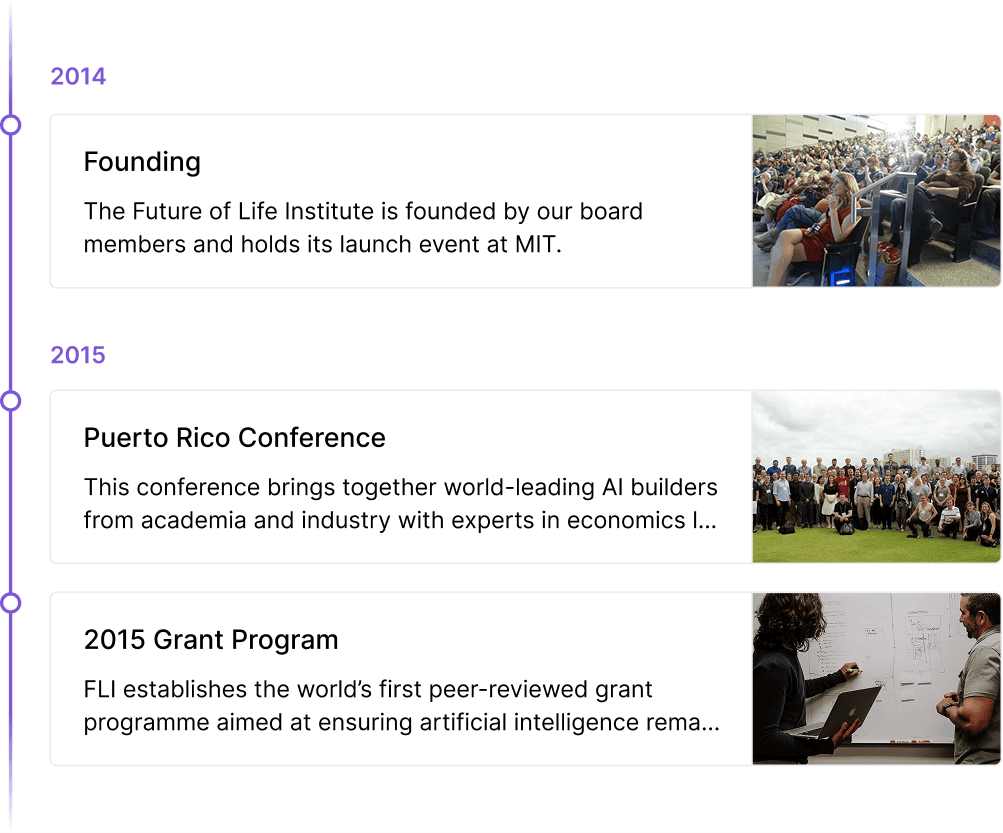
Our History
We’ve been working to safeguard humanity’s future since 2014.
Learn about FLI’s work and achievements since its founding, including historic conferences, grant programs, and open letters that have shaped the course of technology.