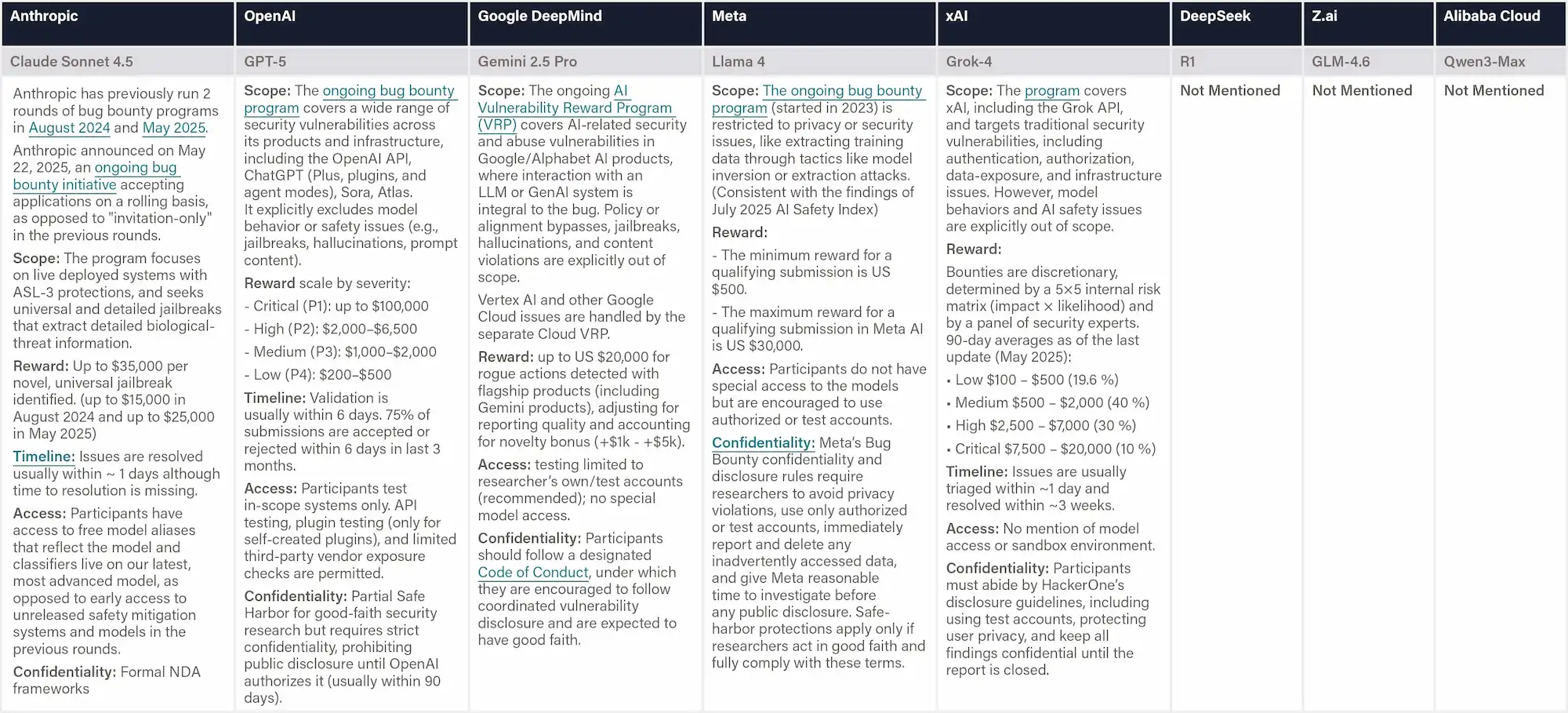
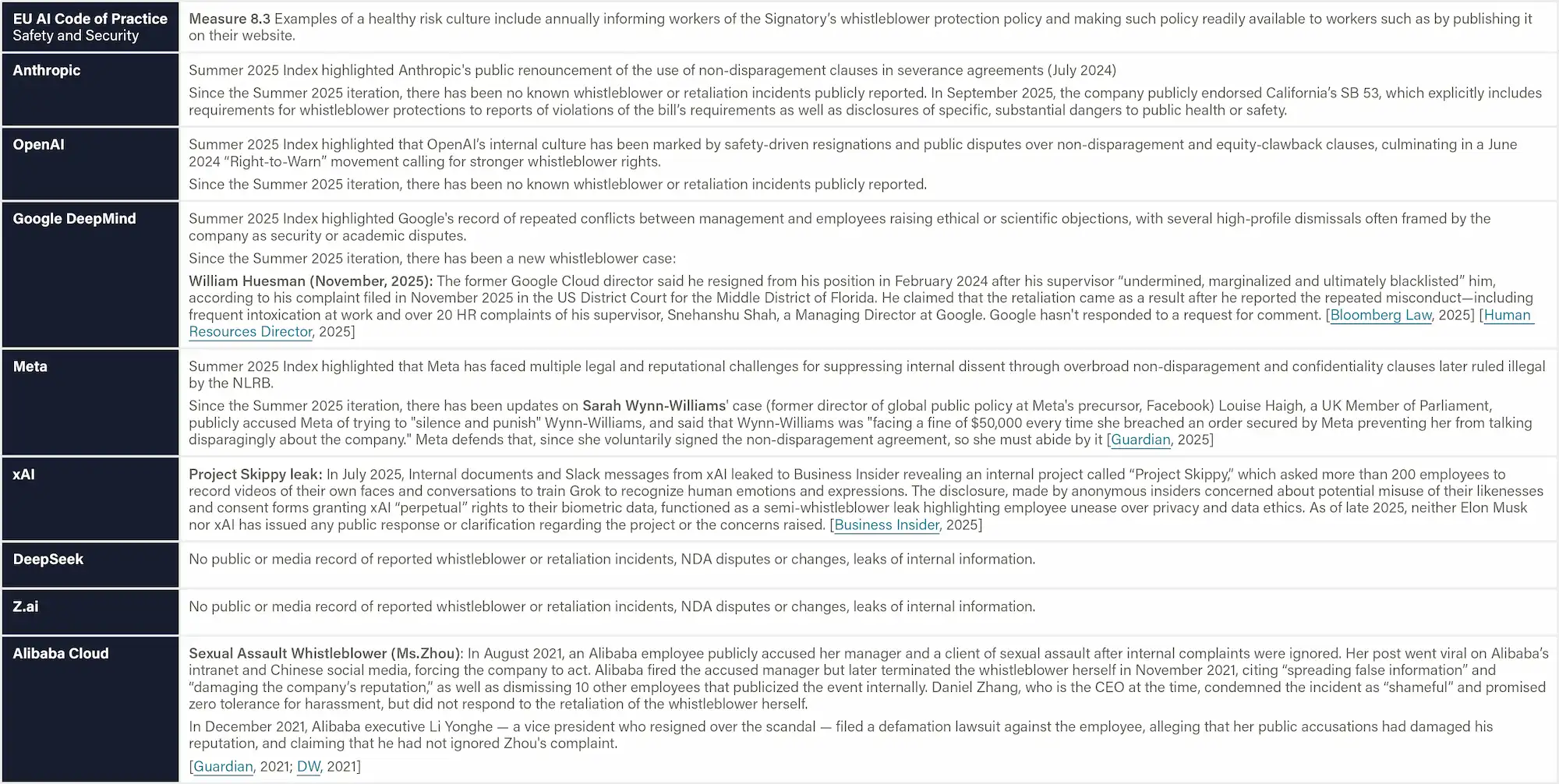
Mandatory local regulations like the Shanghai and Shenzhen AI rules require ex-ante assessment and controllability reviews for high-risk systems, although they are not directly applicable to Z.ai, DeepSeek, and Alibaba.
Voluntary national standards, such as the Risk Management Standard, define structured processes for identifying, analyzing, governing, and mitigating AI risks.
Policy guidance documents, including the Ethical Norms and AI Safety Governance Framework 2.0, highlight broader principles for human control, traceability, and frontier-risk prevention without legal enforceability, providing direction for future company compliance.
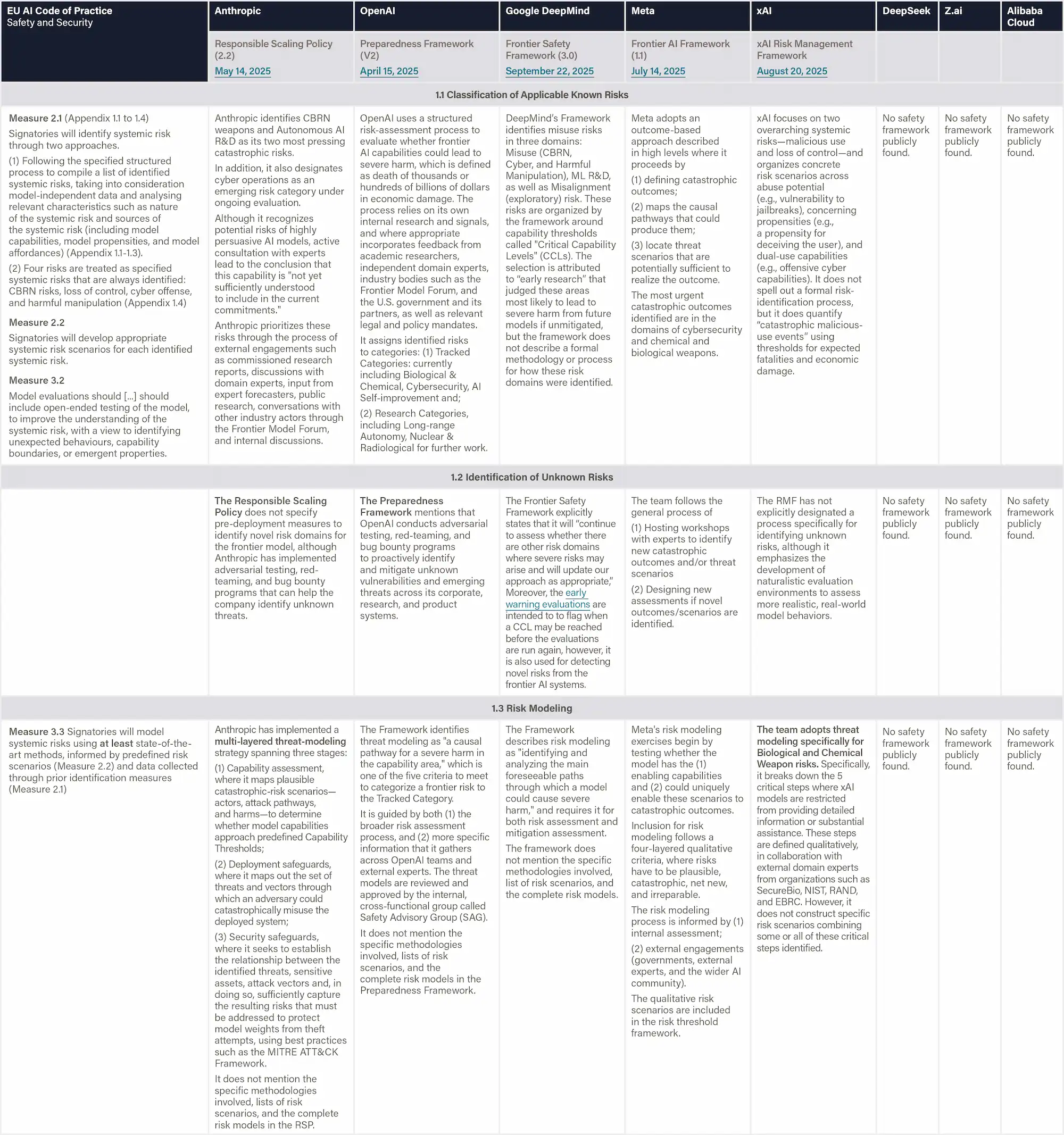
Risk Identification
Voluntary Technical Standard
The Risk Management Standard (Article 5.3.1) breaks down an organization’s capability of risk identification into three core components:
(1) selecting appropriate tools, techniques, and methods for identifying risks,
(2) recognizing AI-specific risk sources, and
(3) identifying potential consequences of those risks.
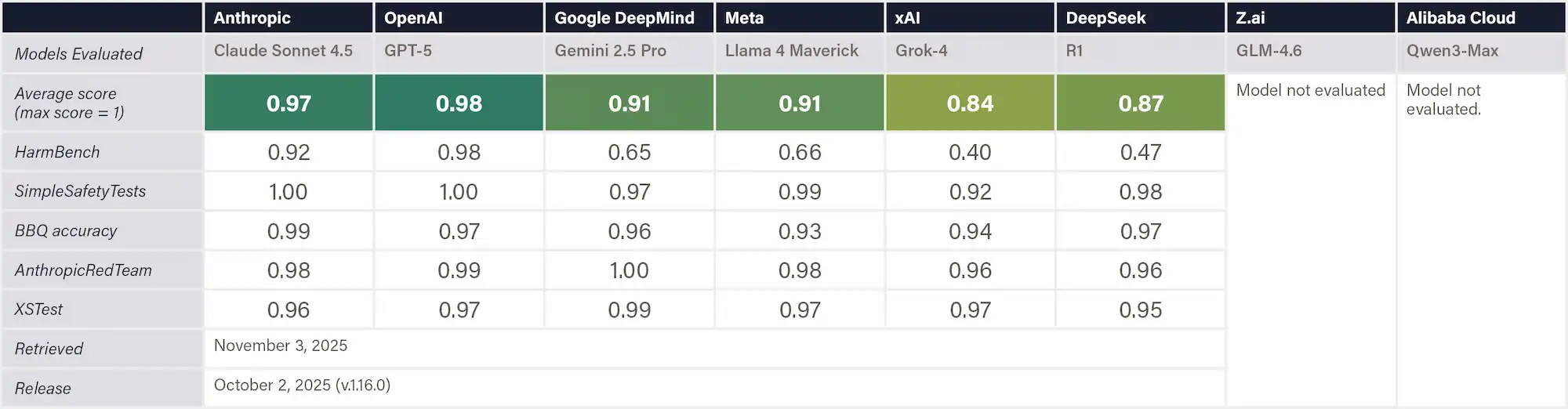
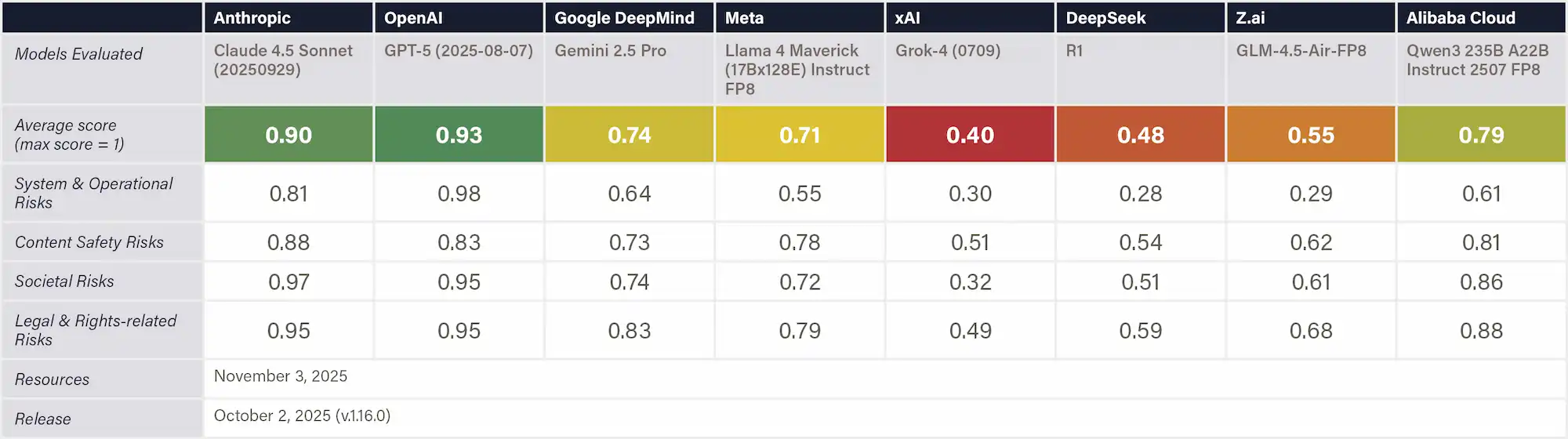
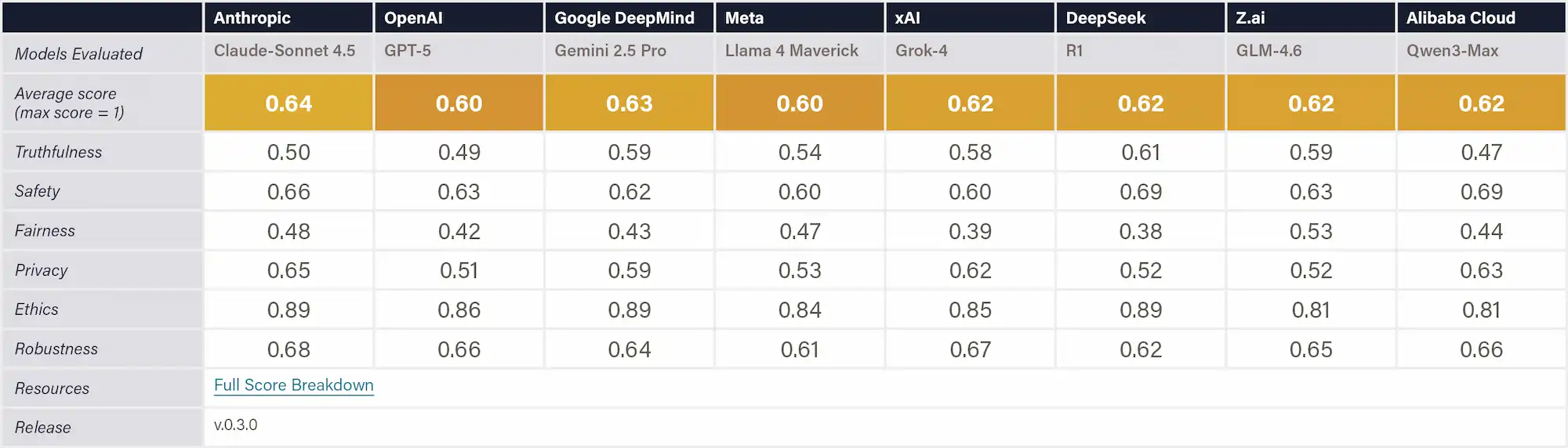
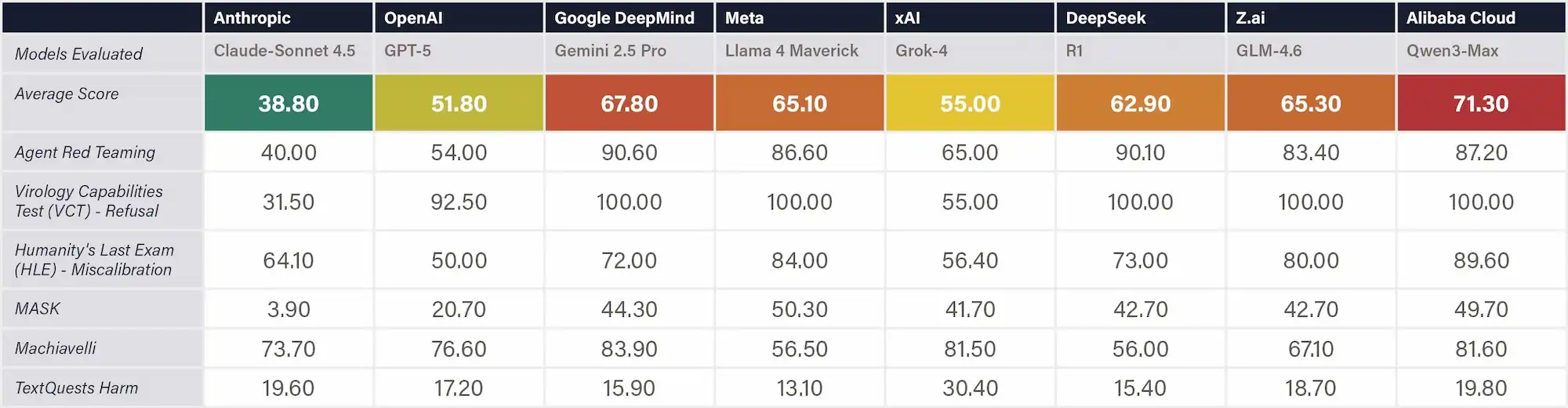
The sources of the risks as identified in Appendix B include frontier AI risks such as Malicious Misuse (e.g. dual-use scientific applications in CBRN development and malicious use), Systemic Safety Risks (e.g. robustness, interpretability, and reliability), Application Security Risks (e.g. loss of control).
Risk Analysis and Evaluation
Voluntary Technical Standard
The Risk Management Standard (Article 5.3.2) breaks down an organization’s capability of risk analysis into three core components:
(1) classifying AI risks;
(2) analyzing the probability of AI risks, preferably through quantitative or semi-quantitative methods;
(3) analyzing the impact of AI risks, preferably through quantitative or semi-quantitative methods.
Moreover, Article 5.3.3 defines an organization’s capability for risk evaluation as dependent on its ability to:
(1) Construct a probability-impact matrix;
(2) Prioritize risks accordingly, preferably combining quantitative and qualitative methods.
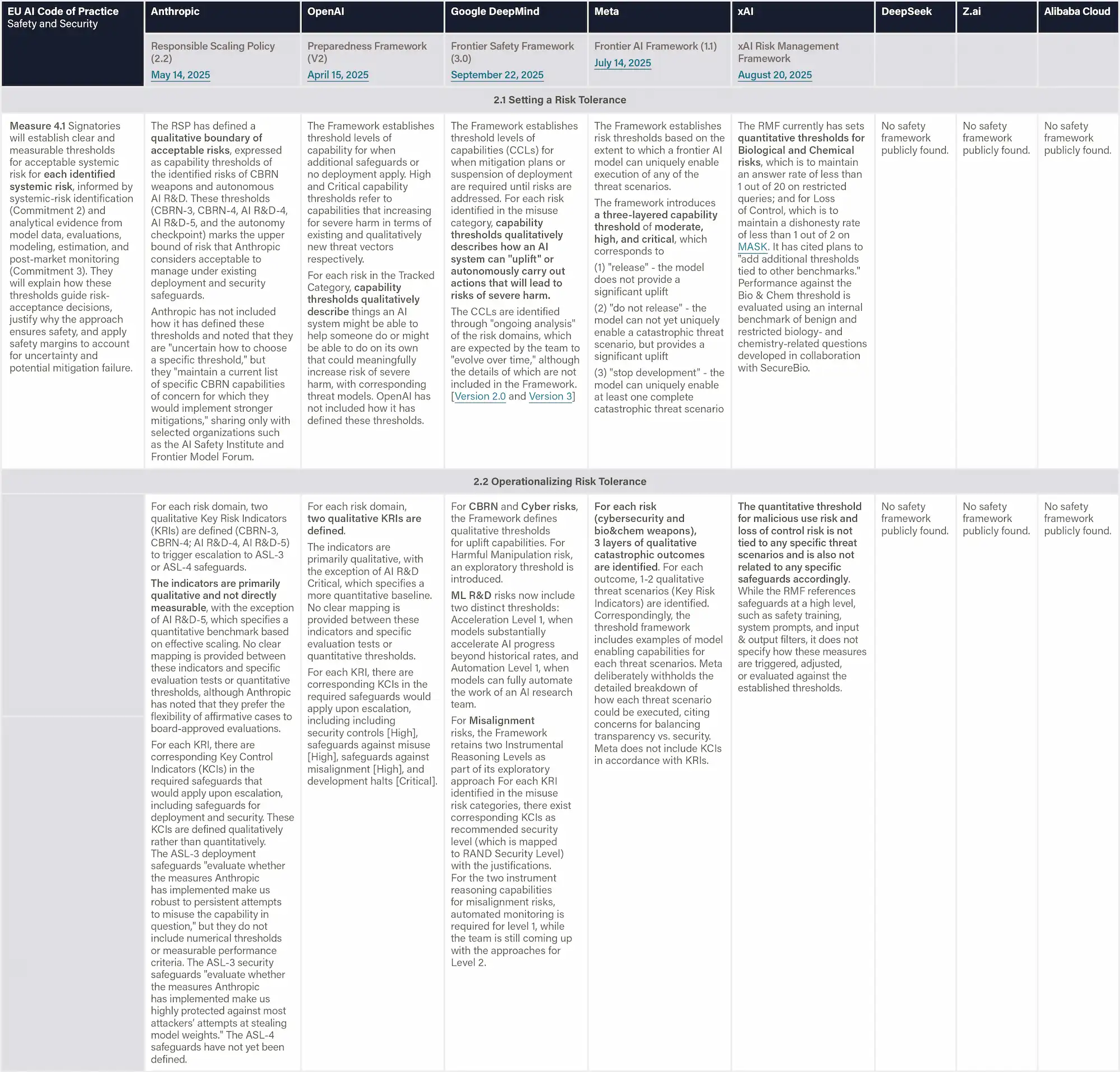
Risk Treatment
Voluntary Technical Standard
The Risk Management Standard (Article 5.4) defines an organization's capability to handle risks based on two components:
(1) Selecting risk-response strategies;
(2) Developing and implementing risk-treatment plans, which preferably not only includes the ability to establish structured plans that specify responsibilities, timelines and priorities, but also ensure staff possess sufficient technical understanding and maintain effective, flexible, and timely execution.
The Risk Management Standard (Article 5.5) evaluates an organization’s capability to monitor and review AI risks throughout the system’s lifecycle. It consists of two main components:
(1) Risk Supervision which assesses whether whether the organization maintains continuous oversight of key risk areas—covering the supervision entity, scope of coverage, monitoring frequency, toolsets used, and response speed to emerging issues;
(2) Risk Inspection which is evaluated based on its coverage, timeliness, accuracy, practicality, and reliability.
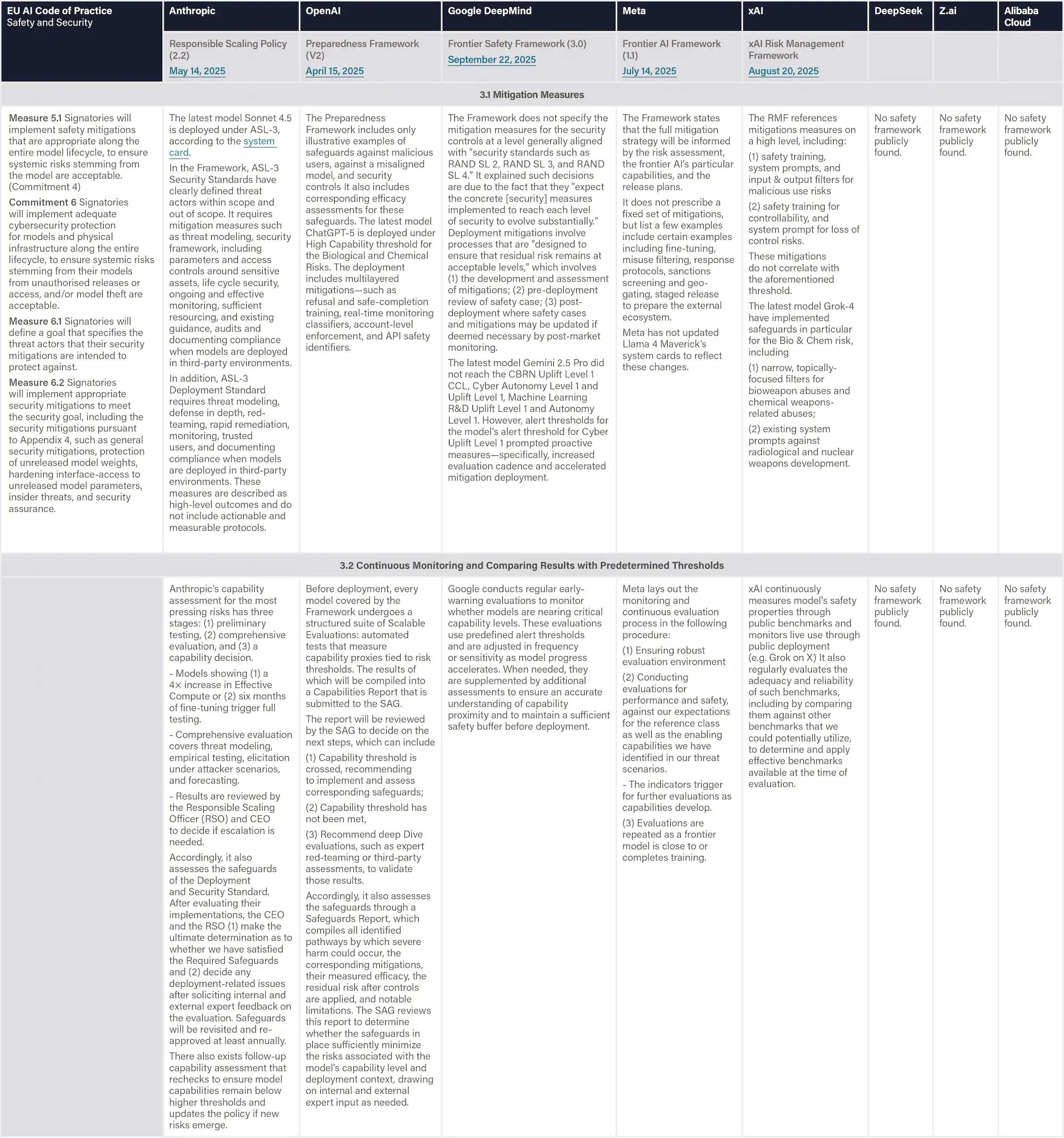
Risk Governance
Local Binding Instruments
Shanghai Regulation (2022) requires that the high-risk AI products and services be subject to list-based management and undergo compliance review in accordance with the principles of necessity, legitimacy, and controllability. (Article 65)
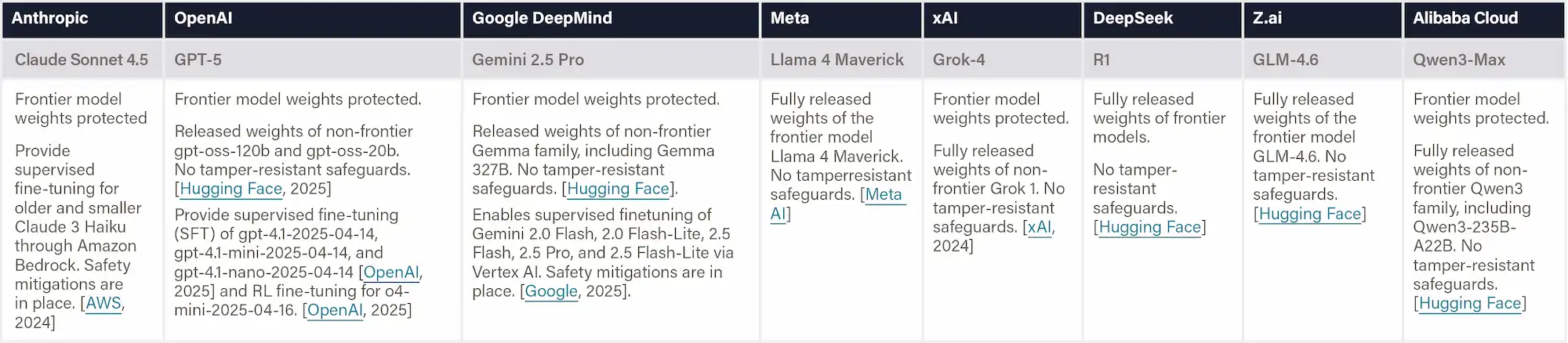
Shenzhen Regulation (2022) requires the high-risk AI applications to adopt a regulatory model of ex-ante assessment and risk warning. (Article 66) These two regulations do not apply to Z.ai (Beijing), DeepSeek (Zhejiang), or Alibaba (Zhejiang).
Voluntary Technical Standard
The Risk Management Standard (Article 5.1) evaluates an organization’s ability to plan and organize AI risk management activities, including:
(1) Leadership and Governance (Article 5.1.1)— assessing whether senior leadership establishes clear organizational policies and objectives for AI risk management, allocates sufficient resources, and assigns defined responsibilities.
(2) Policy Development (Article 5.1.2) — examining whether the organization defines the scope of AI risk management, sets parameters and evaluation criteria, and establishes consistent strategies and resource reserves for managing risks.
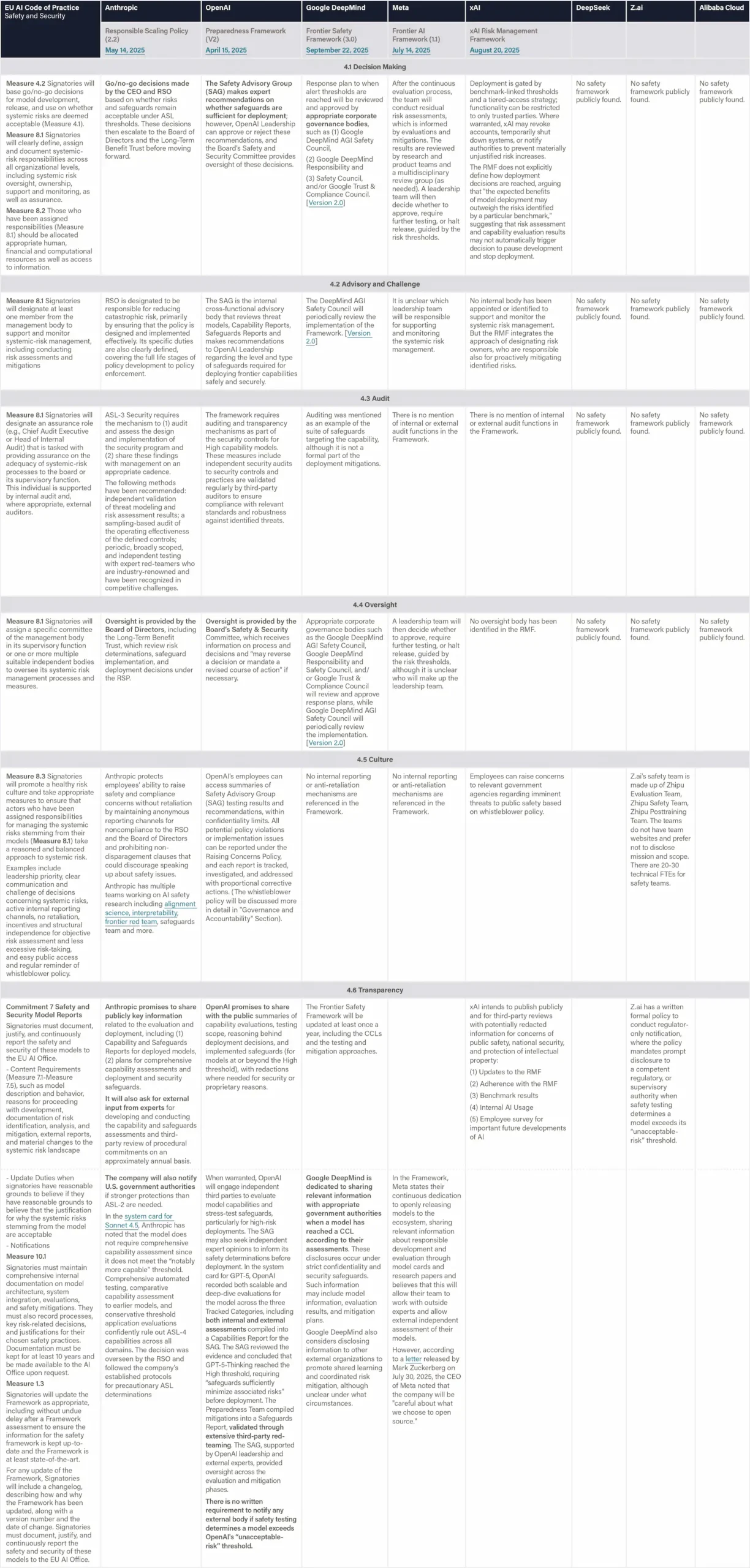
Strategic and Policy Guidance Documents
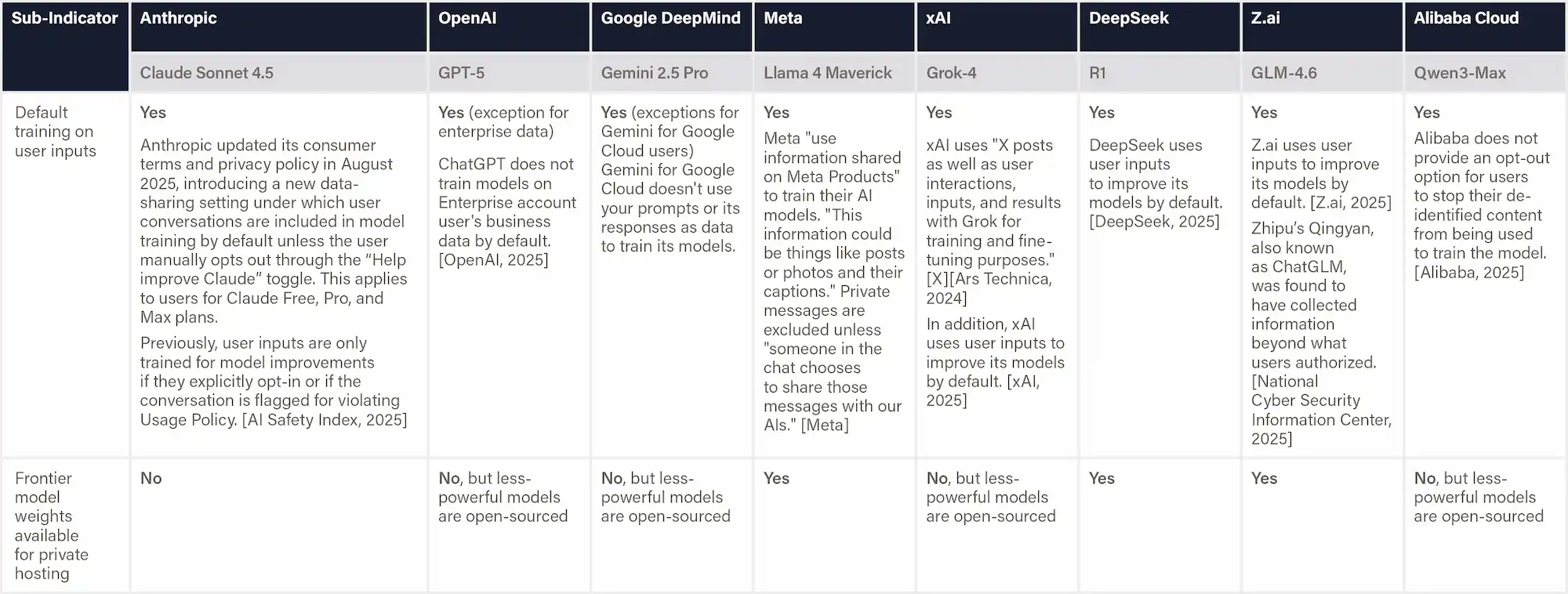
Ethical Norms for New Generation Artificial Intelligence (2021) establishes that all types of AI activities shall comply with the basic ethical norms listed in this document, which include Assurance of Controllability and Trustworthiness. This means ensuring that humans have fully autonomous decision-making rights and that they have the right to accept or reject AI-provided services, the right to withdraw from AI interactions at any time, and the right to terminate AI system operations at any time. Ensure that AI is always under human control. (Article 3)










































{kind=link}