ICLR Safe ML Workshop Report

Contents
This year the ICLR conference hosted topic-based workshops for the first time (as opposed to a single track for workshop papers), and I co-organized the Safe ML workshop. One of the main goals was to bring together near and long term safety research communities.
 The workshop was structured according to a taxonomy that incorporates both near and long term safety research into three areas — specification, robustness, and assurance.
The workshop was structured according to a taxonomy that incorporates both near and long term safety research into three areas — specification, robustness, and assurance.
Specification: define the purpose of the system
- Reward hacking
- Side effects
- Preference learning
- Fairness
Robustness: design system to withstand perturbations
- Adaptation
- Verification
- Worst-case robustness
- Safe exploration
Assurance: monitor and control system activity
- Interpretability
- Monitoring
- Privacy
- Interruptibility
We had an invited talk and a contributed talk in each of the three areas.
Talks
In the specification area, Dylan Hadfield-Menell spoke about formalizing the value alignment problem in the Inverse RL framework.
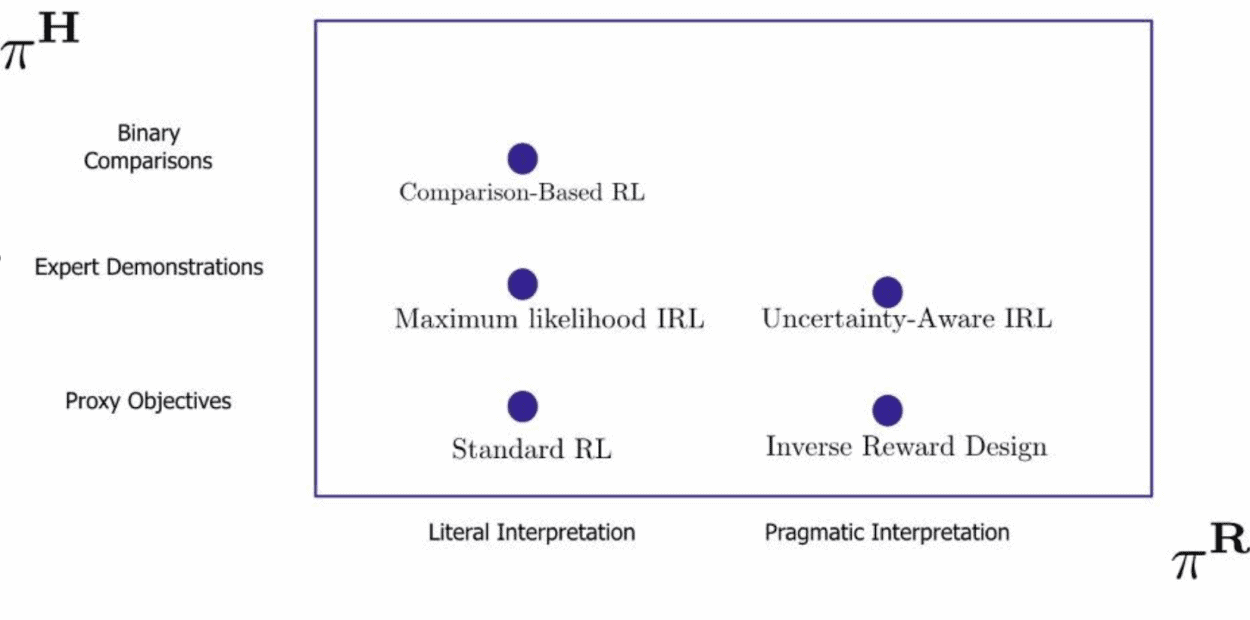
David Krueger presented a paper on hidden incentives for the agent to shift its task distribution in the meta-learning setting.
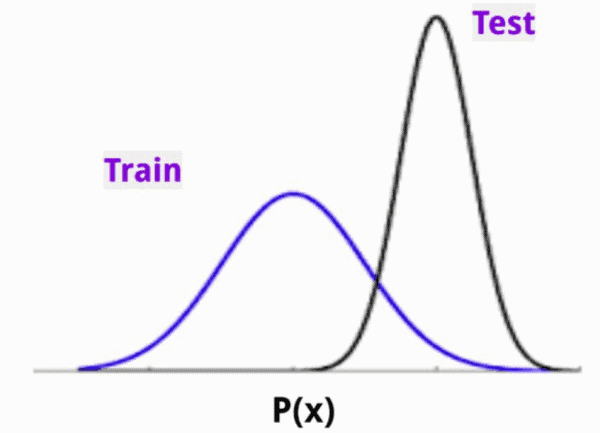
In the robustness area, Ian Goodfellow argued for dynamic defenses against adversarial examples and encouraged the research community to consider threat models beyond small perturbations within a norm ball of the original data point.

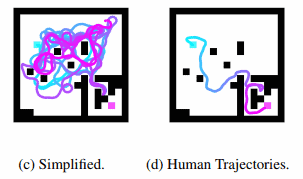
Avraham Ruderman presented a paper on worst-case analysis for discovering surprising behaviors (e.g. failing to find the goal in simple mazes).
In the assurance area, Cynthia Rudin argued that interpretability doesn’t have to trade off with accuracy (especially in applications), and that it is helpful for solving research problems in all areas of safety.

Beomsu Kim presented a paper explaining why adversarial training improves the interpretability of gradients for deep neural networks.

Panels
The workshop panels discussed possible overlaps between different research areas in safety and research priorities going forward.
In terms of overlaps, the main takeaway was that advancing interpretability is useful for all safety problems. Also, adversarial robustness can contribute to value alignment – e.g. reward gaming behaviors can be viewed as a system finding adversarial examples for its reward function. However, there was a cautionary point that while near- and long-term problems are often similar, solutions might not transfer well between these areas (e.g. some solutions to near-term problems might not be sufficiently general to help with value alignment).

The research priorities panel recommended more work on adversarial examples with realistic threat models (as mentioned above), complex environments for testing value alignment (e.g. creating new structures in Minecraft without touching existing ones), fairness formalizations with more input from social scientists, and improving cybersecurity.
Papers
Out of the 35 accepted papers, 5 were on long-term safety / value alignment, and the rest were on near-term safety. Half of the near-term paper submissions were on adversarial examples, so the resulting pool of accepted papers was skewed as well: 14 on adversarial examples, 5 on interpretability, 3 on safe RL, 3 on other robustness, 2 on fairness, 2 on verification, and 1 on privacy. Here is a summary of the value alignment papers:
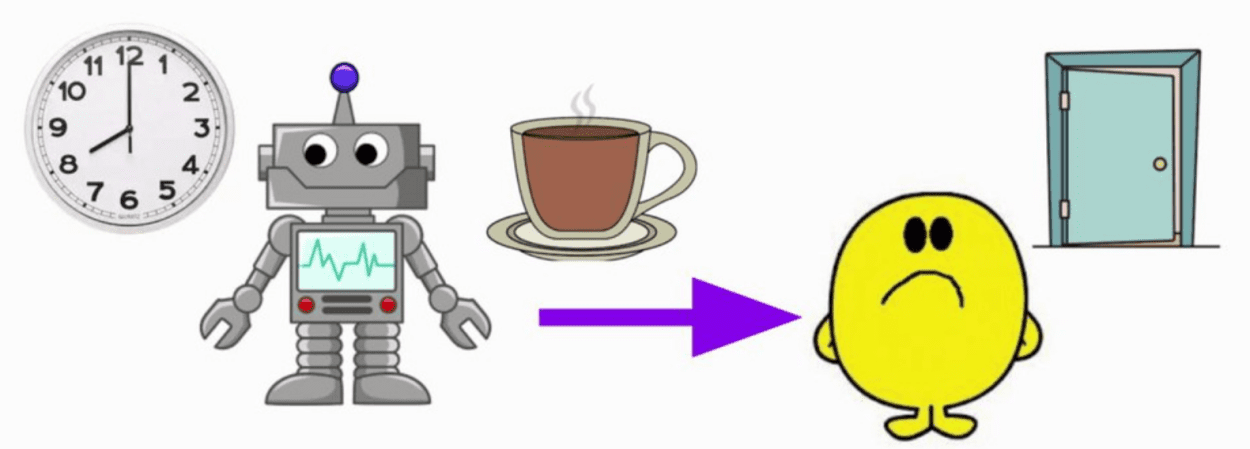
Misleading meta-objectives and hidden incentives for distributional shift by Krueger et al shows that RL agents in a meta-learning context have an incentive to shift their task distribution instead of solving the intended task. For example, a household robot whose task is to predict whether its owner will want coffee could wake up its owner early in the morning to make this prediction task easier. This is called a ‘self-induced distributional shift’ (SIDS), and the incentive to do so is a ‘hidden incentive for distributional shift’ (HIDS). The paper demonstrates this behavior experimentally and shows how to avoid it.
How useful is quantilization for mitigating specification-gaming? by Ryan Carey introduces variants of several classic environments (Mountain Car, Hopper and Video Pinball) where the observed reward differs from the true reward, creating an opportunity for the agent to game the specification of the observed reward. The paper shows that a quantilizing agent avoids specification gaming and performs better in terms of true reward than both imitation learning and a regular RL agent on all the environments.
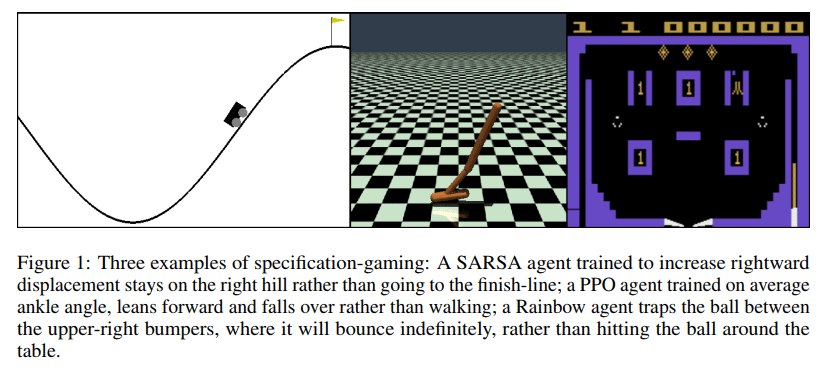
Delegative Reinforcement Learning: learning to avoid traps with a little help by Vanessa Kosoy introduces an RL algorithm that avoids traps in the environment (states where regret is linear) by delegating some actions to an external advisor, and achieves sublinear regret in a continual learning setting. (Summarized in Alignment Newsletter #57)

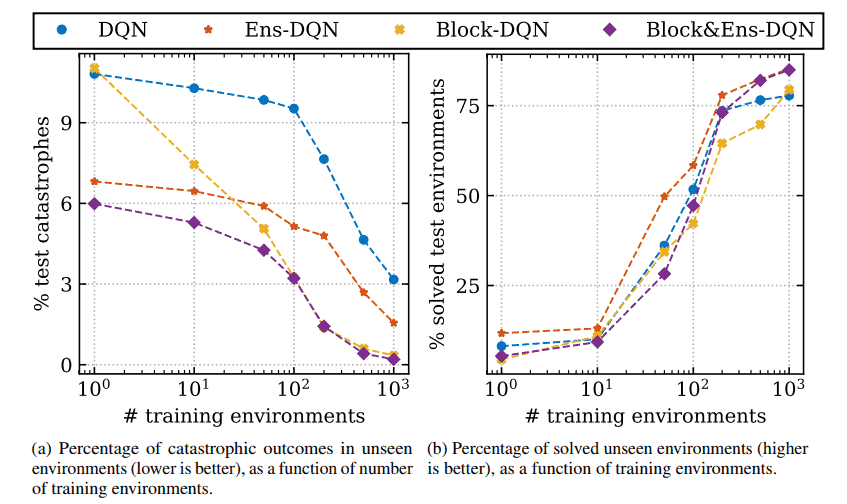
Generalizing from a few environments in safety-critical reinforcement learning by Kenton et al investigates how well RL agents avoid catastrophes in new gridworld environments depending on the number of training environments. They find that both model ensembling and learning a catastrophe classifier (used to block actions) are helpful for avoiding catastrophes, with different safety-performance tradeoffs on new environments.
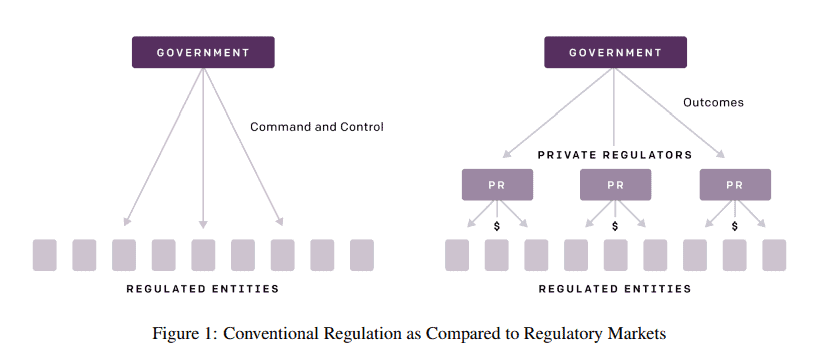
Regulatory markets for AI safety by Clark and Hadfield proposes a new model for regulating AI development where regulation targets are required to choose regulatory services from a private market that is overseen by the government. This allows regulation to efficiently operate on a global scale and keep up with the pace of technological development and better ensure safe deployment of AI systems. (Summarized in Alignment Newsletter #55)
The workshop got a pretty good turnout (around 100 people). Thanks everyone for participating, and thanks to our reviewers, sponsors, and my fellow organizers for making it happen!

(Cross-posted from the Deep Safety blog.)
About the Future of Life Institute
The Future of Life Institute (FLI) is the world’s oldest and largest AI think tank, with a team of 35+ full-time staff operating across the US and Europe. FLI has been working to steer the development of transformative technologies towards benefitting life and away from extreme large-scale risks since its founding in 2014. Find out more about our mission or explore our work.
Related content
Other posts about AI, Recent News

Should AIs be people too?

Governor DeSantis Directs Florida State Agencies to Partner with Future of Life Institute to Shield Families from AI Harm

Statement from Max Tegmark on the Department of War’s ultimatum
