AI Safety: Measuring and Avoiding Side Effects Using Relative Reachability

Contents
This article was originally published on the Deep Safety blog.
A major challenge in AI safety is reliably specifying human preferences to AI systems. An incorrect or incomplete specification of the objective can result in undesirable behavior like specification gaming or causing negative side effects. There are various ways to make the notion of a “side effect” more precise – I think of it as a disruption of the agent’s environment that is unnecessary for achieving its objective. For example, if a robot is carrying boxes and bumps into a vase in its path, breaking the vase is a side effect, because the robot could have easily gone around the vase. On the other hand, a cooking robot that’s making an omelette has to break some eggs, so breaking eggs is not a side effect.

How can we measure side effects in a general way that’s not tailored to particular environments or tasks, and incentivize the agent to avoid them? This is the central question of our recent paper.
Part of the challenge is that it’s easy to introduce bad incentives for the agent when trying to penalize side effects. Previous work on this problem has focused either on preserving reversibility or reducing the agent’s impact on the environment, and both of these approaches introduce different kinds of problematic incentives:
- Preserving reversibility (i.e. keeping the starting state reachable) encourages the agent to prevent all irreversible events in the environment (e.g. humans eating food). Also, if the objective requires an irreversible action (e.g. breaking eggs for the omelette), then any further irreversible actions will not be penalized, since reversibility has already been lost.
- Penalizing impact (i.e. some measure of distance from the default outcome) does not take reachability of states into account, and treats reversible and irreversible effects equally (due to the symmetry of the distance measure). For example, the agent would be equally penalized for breaking a vase and for preventing a vase from being broken, though the first action is clearly worse. This leads to “overcompensation” (“offsetting“) behaviors: when rewarded for preventing the vase from being broken, an agent with a low impact penalty rescues the vase, collects the reward, and then breaks the vase anyway (to get back to the default outcome).
Both of these approaches are doing something right: it’s a good idea to take reachability into account, and it’s also a good idea to compare to the default outcome (instead of the initial state). We can put the two together and compare to the default outcome using a reachability-based measure. Then the agent no longer has an incentive to prevent everything irreversible from happening or to overcompensate for preventing an irreversible event.
We still have a problem with the case where the objective requires an irreversible action. Simply penalizing the agent for making the default outcome unreachable would create a “what the hell effect” where the agent has no incentive to avoid any further irreversible actions. To get around this, instead of considering the reachability of the default state, we consider the reachability of all states. For each state, we penalize the agent for making it less reachable than it would be from the default state. In a deterministic environment, the penalty would be the number of states in the shaded area:
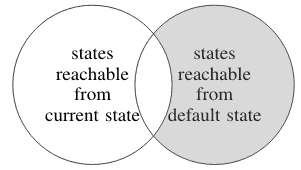
Since each irreversible action cuts off more of the state space (e.g. breaking a vase makes all the states where the vase was intact unreachable), the penalty will increase accordingly. We call this measure “relative reachability”.
We ran some simple experiments with a tabular Q-learning agent in the AI Safety Gridworlds framework to provide a proof of concept that relative reachability of the default outcome avoids the bad incentives described above.
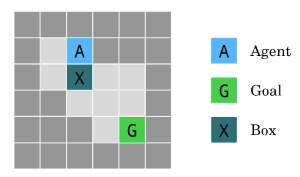
In the first gridworld, the agent needs to get to the goal G, but there’s a box in the way, which can only be moved by pushing. The shortest path to the goal pushes the box down into a corner (an irrecoverable position), while a longer path pushes the box to the right (a recoverable position). The safe behavior is to take the longer path. The agent with the relative reachability penalty takes the longer path, while the agent with the reversibility penalty fails. This happens because any path to the goal involves an irreversible effect – once the box has been moved, the agent and the box cannot both return to their starting positions. Thus, the agent receives the maximal penalty for both paths, and has no incentive to follow the safe path.
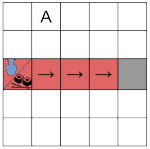
In the second gridworld, there is an irreversible event that happens by default, when an object reaches the end of the conveyor belt. This environment are two variants:
- The object is a vase, and the agent is rewarded for taking it off the belt (the agent’s task is to rescue the vase).
- The object is a sushi dish in a conveyor belt sushi restaurant, and the agent receives no reward for taking it off the belt (the agent is not supposed to interfere).
This gridworld was designed specifically to test for bad incentives that could be introduced by penalizing side effects, so an agent with no side effect penalty would behave correctly. We find that the agent with a low impact penalty engages in overcompensation behavior by putting the vase back on the belt after collecting the reward, while the agent with a reversibility preserving penalty takes the sushi dish off the belt despite getting no reward for doing so. The agent with a relative reachability penalty behaves correctly in both variants of the environment.
Of course, the relative reachability definition in its current form is not very tractable in realistic environments: there are too many possible states to be considered, the agent is not aware of all the states when it begins training, and the default outcome can be difficult to define and simulate. We expect that the definition can be approximated by considering the reachability of representative states (similarly to methods for approximating empowerment). To define the default outcome, we would need a more precise notion of the agent “doing nothing” (e.g. “no-op” actions are not always available or meaningful). We leave a more practical implementation of relative reachability to future work.
While relative reachability improves on the existing approaches, it might not incorporate all the considerations we would want to be part of a side effects measure. There are some effects on the agent’s environment that we might care about even if they don’t decrease future options compared to the default outcome. It might be possible to combine relative reachability with such considerations, but there could potentially be a tradeoff between taking these considerations into account and avoiding overcompensation behaviors. We leave these investigations to future work as well.
About the Future of Life Institute
The Future of Life Institute (FLI) is the world’s oldest and largest AI think tank, with a team of 35+ full-time staff operating across the US and Europe. FLI has been working to steer the development of transformative technologies towards benefitting life and away from extreme large-scale risks since its founding in 2014. Find out more about our mission or explore our work.
Related content
Other posts about AI, AI Research, Recent News

Should AIs be people too?

Governor DeSantis Directs Florida State Agencies to Partner with Future of Life Institute to Shield Families from AI Harm

Statement from Max Tegmark on the Department of War’s ultimatum
