AI Safety Highlights from NIPS 2016

Contents
This year’s Neural Information Processing Systems (NIPS) conference was larger than ever, with almost 6000 people attending, hosted in a huge convention center in Barcelona, Spain. The conference started off with two exciting announcements on open-sourcing collections of environments for training and testing general AI capabilities – the DeepMind Lab and the OpenAI Universe. Among other things, this is promising for testing safety properties of ML algorithms. OpenAI has already used their Universe environment to give an entertaining and instructive demonstration of reward hacking that illustrates the challenge of designing robust reward functions.
I was happy to see a lot of AI-safety-related content at NIPS this year. The ML and the Law symposium and Interpretable ML for Complex Systems workshop focused on near-term AI safety issues, while the Reliable ML in the Wild workshop also covered long-term problems. Here are some papers relevant to long-term AI safety:
Inverse Reinforcement Learning
Cooperative Inverse Reinforcement Learning (CIRL) by Hadfield-Menell, Russell, Abbeel, and Dragan (main conference). This paper addresses the value alignment problem by teaching the artificial agent about the human’s reward function, using instructive demonstrations rather than optimal demonstrations like in classical IRL (e.g. showing the robot how to make coffee vs having it observe coffee being made). (3-minute video)

Generalizing Skills with Semi-Supervised Reinforcement Learning by Finn, Yu, Fu, Abbeel, and Levine (Deep RL workshop). This work addresses the scalable oversight problem by proposing the first tractable algorithm for semi-supervised RL. This allows artificial agents to robustly learn reward functions from limited human feedback. The algorithm uses an IRL-like approach to infer the reward function, using the agent’s own prior experiences in the supervised setting as an expert demonstration.
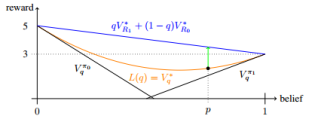
Towards Interactive Inverse Reinforcement Learning by Armstrong and Leike (Reliable ML workshop). This paper studies the incentives of an agent that is trying to learn about the reward function while simultaneously maximizing the reward. The authors discuss some ways to reduce the agent’s incentive to manipulate the reward learning process.
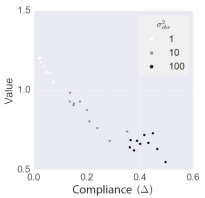
Should Robots Have Off Switches? by Milli, Hadfield-Menell, and Russell (Reliable ML workshop). This poster examines some adverse effects of incentivizing artificial agents to be compliant in the off-switch game (a variant of CIRL).
Safe Exploration
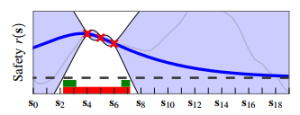
Safe Exploration in Finite Markov Decision Processes with Gaussian Processes by Turchetta, Berkenkamp, and Krause (main conference). This paper develops a reinforcement learning algorithm called Safe MDP that can explore an unknown environment without getting into irreversible situations, unlike classical RL approaches.
Combating Reinforcement Learning’s Sisyphean Curse with Intrinsic Fear by Lipton, Gao, Li, Chen, and Deng (Reliable ML workshop). This work addresses the ‘Sisyphean curse’ of DQN algorithms forgetting past experiences, as they become increasingly unlikely under a new policy, and therefore eventually repeating catastrophic mistakes. The paper introduces an approach called ‘intrinsic fear’, which maintains a model for how likely different states are to lead to a catastrophe within some number of steps.
Most of these papers were related to inverse reinforcement learning – while IRL is a promising approach, it would be great to see more varied safety material at the next NIPS. There were some more safety papers on other topics at UAI this summer: Safely Interruptible Agents (formalizing what it means to incentivize an agent to obey shutdown signals) and A Formal Solution to the Grain of Truth Problem (providing a broad theoretical framework for multiple agents learning to predict each other in arbitrary computable games).
These highlights were originally posted here and cross-posted to Approximately Correct. Thanks to Jan Leike, Zachary Lipton, and Janos Kramar for providing feedback on this post.
About the Future of Life Institute
The Future of Life Institute (FLI) is a global think tank with a team of 20+ full-time staff operating across the US and Europe. FLI has been working to steer the development of transformative technologies towards benefitting life and away from extreme large-scale risks since its founding in 2014. Find out more about our mission or explore our work.
Related content
Other posts about AI, Recent News



