AlphaGo and AI Progress

Contents
Tomorrow, March 9, DeepMind’s AlphaGo begins its quest to beat the reigning world champion of Go, Lee Se-dol. In anticipation of the event, we’re pleased to feature this excellent overview of the impact of AlphaGo on the AI field, written by Miles Brundage. Don’t forget to tune in to Youtube March 9-15 for the full tournament!
Introduction
AlphaGo’s victory over Fan Hui has gotten a lot of press attention, and relevant experts in AI and Go have generally agreed that it is a significant milestone. For example, Jon Diamond, President of the British Go Association, called the victory a “large, sudden jump in strength,” and AI researchers Francesca Rossi, Stuart Russell, and Bart Selman called it “important,” “impressive,” and “significant,” respectively.
How large/sudden and important/impressive/significant was AlphaGo’s victory? Here, I’ll try to at least partially answer this by putting it in a larger context of recent computer Go history, AI progress in general, and technological forecasting. In short, it’s an impressive achievement, but considering it in this larger context should cause us to at least slightly decrease our assessment of its size/suddenness/significance in isolation. Still, it is an enlightening episode in AI history in other ways, and merits some additional commentary/analysis beyond the brief snippets of praise in the news so far. So in addition to comparing the reality to the hype, I’ll try to distill some general lessons from AlphaGo’s first victory about the pace/nature of AI progress and how we should think about its upcoming match against Lee Sedol.
What happened
AlphaGo, a system designed by a team of 15-20 people[1] at Google DeepMind, beat Fan Hui, three-time European Go champion, in 5 out of 5 formal games of Go. Hui also won 2 out of 5 informal games with less time per move (for more interesting details often unreported in press accounts, see also the relevant Nature paper). The program is stronger at Go than all previous Go engines (more on the question of how much stronger below).
How it was done
AlphaGo was developed by a relatively large team (compared to those associated with other computer Go programs), using significant computing resources (more on this below). The program combines neural networks and Monte Carlo tree search (MCTS) in a novel way, and was trained in multiple phases involving both supervised learning and self-play. Notably from the perspective of evaluating its relation to AI progress, it was not trained end-to-end (though according to Demis Hassabis at AAAI 2016, they may try to do this in the future). It also used some hand-crafted features for the MCTS component (another point often missed by observers). The claimed contributions of the relevant paper are the ideas of value and policy networks, and the way they are integrated with MCTS. Data in the paper indicate that the system was stronger with these elements than without them.
Overall AI performance vs. algorithm-specific progress
Among other insights that can be gleaned from a careful study of the AlphaGo Nature paper, one is particularly relevant for assessing the broader significance of this result: the critical role that hardware played in improving AlphaGo’s performance. Consider the figures below, which I’ll try to contextualize.
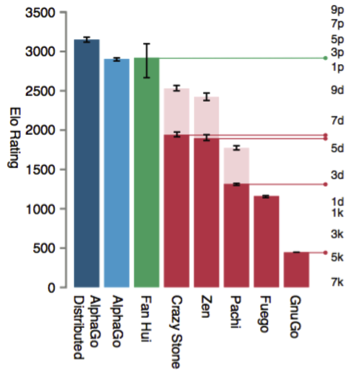
I’ll say more about the differences between these two, and other AlphaGo variants, below, but for now, note one thing that’s missing from this figure: very recent Go programs. In the weeks and months leading up to AlphaGo’s victory, there was significant activity and enthusiasm (though by much smaller terms, e.g. 1-2 at Facebook) in the Go community about two Go engines – darkforest (and its variants, with the best being darkfmcts3) made by researchers at Facebook, and Zen19X, a new and experimental version of the highly ranked Zen program. Note that in January of this year, Zen19X was briefly ranked in the 7d range on the KGS Server (used for human and computer Go), reportedly due to the incorporation of neural networks. Darkfmcts3 achieved a solid 5d ranking, a 2-3 dan improvement over where it was just a few months earlier, and the researchers behind it indicated in papers that there were various readily available ways to improve it. Indeed, in the most recent KGS Computer Go tournament, according to the most recent version of their paper on these programs, Tian and Zhu said that they would have won against a Zen variant if not for a glitch (contra Hassabis who said darkfmcts3 lost to Zen – he may not have read the relevant footnote!). Computer Go, to summarize, was already seeing a lot of progress via the incorporation of deep learning prior to AlphaGo, and this would slightly reduce the delta in the figure above (which was probably produced a few months ago), but not eliminate it entirely.
So, back to the hardware issue. Silver and Huang et al. at DeepMind evaluated many variants of AlphaGo, summarized as AlphaGo and AlphaGo Distributed in the figure above. But this does not give a complete picture of the variation driven by hardware differences, which the next figure (also from the paper) sheds light on.
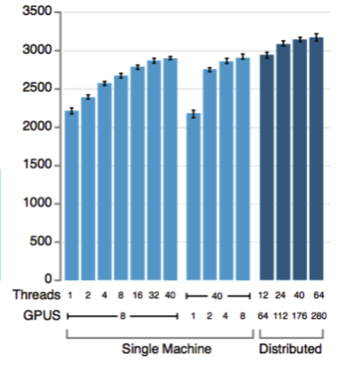
This figure shows the estimated Elo rating of several variants of AlphaGo. The 11 light blue bars are from “single machine” variants, and the dark blue ones involve distributing AlphaGo across multiple machines. But what is this machine exactly? The “threads” indicated here are search threads, and by looking in a later figure in the paper, we can find that the least computationally intensive AlphaGo version (the shortest bar shown here) used 48 CPUs and 1 GPU. For reference, Crazy Stone does not use any GPUs, and uses slightly fewer CPUs. After a brief search into the clusters currently used for different Go programs, I was unable to find any using more than 36 or so CPUs. Facebook’s darkfmcts3 is the only version I know of that definitely uses GPUs, and it uses 64 GPUs in the biggest version and 8 CPUs (so, more GPUs than single machine AlphaGo, but fewer CPUs). The single machine AlphaGo bar used in the previous figure, which indicated a large delta over prior programs, was based on the 40 search thread/48 CPU/8 GPU variant. If it were to show the 48 CPU/1 GPU version, it would be only slightly higher than Crazy Stone and Zen – and possibly not even higher than the very latest Zen19X version, which may have improved since January.
Perhaps the best comparison to evaluate AlphaGo against would be darkfmcts3 on equivalent hardware, but they use different configurations of CPUs/GPUs and darkfmcts3 is currently offline following AlphaGo’s victory. It would also be interesting to try scaling up Crazy Stone or Zen19X to a cluster comparable to AlphaGo Distributed, to further parse the relative gains in hardware-adjusted performance discussed earlier. In short, it’s not clear how much of a gain in performance there was over earlier Go programs for equivalent hardware – probably some, but certainly not as great as between earlier Go programs on small clusters and AlphaGo on the massive cluster ultimately used, which we turn to next.
AlphaGo Distributed, in its largest variant, used 280 GPUs and 1920 CPUs. This is significantly more computational power than any prior reported Go program used, and a lot of hardware in absolute terms. The size of this cluster is noteworthy for two reasons. First, it calls into question the extent of the hardware-adjusted algorithmic progress that AlphaGo represents, and relatedly, the importance of the value and policy networks. If, as I’ve suggested in a recent AAAI workshop paper, “Modeling Progress in AI,” we should keep track of multiple states of the art in AI as opposed to a singular state of the art, then comparing AlphaGo Distributed to, e.g. CrazyStone, is to compare two distinct states of the art – performance given small computational power (and a small team, for that matter) and performance given massive computational power and the efforts of over a dozen of the best AI researchers in the world.
Second, it is notable that hardware alone enabled AlphaGo to span a very large range of skill levels (in human terms) – at the lowest reported level, around an Elo score of 2200, up to well over 3000, which is the difference between amateur and pro level skills. This may suggest (an issue I’ll return to again below) that in the space of possible skill levels, humans occupy a fairly small band. It seems possible that if this project had been carried out, say, 10 or 20 years from now, the skill level gap traversed thanks to hardware could have been from amateur to superhuman (beyond pro level) in one leap, with the same algorithmic foundation. Moreover, 10 or 20 years ago, even with the same algorithms, it would likely not have been possible to develop a superhuman Go agent using this set of algorithms. Perhaps it was only around now that the AlphaGo project made sense to undertake, given progress in hardware (though other developments in recent years also made a difference, like neural network improvements and MCTS).
Additionally, as also discussed briefly in “Modeling Progress in AI,” we should take into account the relationship between AI performance and the data used for training when assessing the rate of progress. AlphaGo used a large game dataset from the KGS servers – I have not yet looked carefully at what data other comparable AIs have used to train on in the past, but it seems possible that this dataset, too, helped enable AlphaGo’s performance. Hassabis at AAAI indicated DeepMind’s intent to try to train AlphaGo entirely with self-play. This would be more impressive, but until that happens, we may not know how much of AlphaGo’s performance depended on the availability of this dataset, which DeepMind gathered on its own from the KGS servers.
Finally, in addition to adjusting for hardware and data, we should also adjust for effort in assessing how significant an AI milestone is. With Deep Blue, for example, significant domain expertise was used to develop the AI that beat Gary Kasparov, rather than a system learning from scratch and thus demonstrating domain-general intelligence. Hassabis at AAAI and elsewhere has argued that AlphaGo represents more general progress in AI than did Deep Blue, and that the techniques used were general purpose. However, the very development of the policy and value network ideas for this project, as well as the specific training regimen used (a sequence of supervised learning and self-play, rather than end-to-end learning), was itself informed by the domain-specific expertise of researchers like David Silver and Aja Huang, who have substantial computer Go and Go expertise. While AlphaGo ultimately exceeded their skill levels, the search for algorithms in this case was informed by this specific domain (and, as mentioned earlier, part of the algorithm encoded domain-specific knowledge – namely, the MCTS component). Also, the team was large –15-20 people, significantly more than prior Go engines that I’m aware of, and more comparable to large projects like Deep Blue or Watson in terms of effort than anything else in computer Go history. So, if we should reasonably expect a large team of some of the smartest, most expert people in a given area working on a problem to yield progress on that problem, then the scale of this effort suggests we should slightly update downwards our impression of the significance of the AlphaGo milestone. This is in contrast to what we should have thought if, e.g. DeepMind had simply taken their existing DQN algorithm, applied it to Go, and achieved the same result. At the same time, innovations inspired by a specific domain may have broad relevance, and value/policy networks may be a case of this. It’s still a bit early to say.
In conclusion, while it may turn out that value and policy networks represent significant progress towards more general and powerful AI systems, we cannot necessarily infer that just from AlphaGo having performed well, without first adjusting for hardware, data, and effort. Also, regardless of whether we see the algorithmic innovations as particularly significant, we should still interpret these results as signs of the scalability of deep reinforcement learning to larger hardware and more data, as well as the tractability of previously-seen-as-difficult problems in the face of substantial AI expert effort, which themselves are important facts about the world to be aware of.
Expert judgment and forecasting in AI and Go
In the wake of AlphaGo’s victory against Fan Hui, much was made of the purported suddenness of this victory relative to expected computer Go progress. In particular, people at DeepMind and elsewhere have made comments to the effect that experts didn’t think this would happen for another decade or more. One person who said such a thing is Remi Coulom, designer of CrazyStone, in a piece in Wired magazine. However, I’m aware of no rigorous effort to elicit expert opinion on the future of computer Go, and it was hardly unanimous that this milestone was that long off. I and others, well before AlphaGo’s victory was announced, said on Twitter and elsewhere that Coulom’s pessimism wasn’t justified. Alex Champandard noted that at a gathering of game AI experts a year or so ago, it was generally agreed that Go AI progress could be accelerated by a concerted effort by Google or others. At AAAI last year, I also asked Michael Bowling, who knows a thing or two about game AI milestones (having developed the AI that essentially solved limit heads-up Texas Hold Em), how long it would take before superhuman Go AI existed, and he gave it a maximum of five years. So, again, this victory being sudden was not unanimously agreed upon, and claims that it was long off are arguably based on cherry-picked and unscientific expert polls.
Still, it did in fact surprise some people, including AI experts, and people like Remi Coulom are hardly ignorant of Go AI. So, if this was a surprise to experts, should that itself be surprising? No. Expert opinion on the future of AI has long been known to be unreliable. I survey some relevant literatures on this issue in “Modeling Progress in AI,” but briefly, we already knew that model-based forecasts beat intuitive judgments, that quantitative technology forecasts generally beat qualitative ones, and various other things that should have led us to not take specific gut feelings (as opposed to formal models/extrapolations thereof) about the future of Go AI that seriously. And among the few actual empirical extrapolations that were made of this, they weren’t that far off.
Hiroshi Yamashita extrapolated the trend of computer Go progress as of 2011 into the future andpredicted a crossover point to superhuman Go in 4 years, which was one year off. In recent years, there was a slowdown in the trend (based on highest KGS rank achieved) that probably would have lead Yamashita or others to adjust their calculations if they had redone them, say, a year ago, but in the weeks leading up to AlphaGo’s victory, again, there was another burst of rapid computer Go progress. I haven’t done a close look at what such forecasts would have looked like at various points in time, but I doubt they would have suggested 10 years or more to a crossover point, especially taking into account developments in the last year. Perhaps AlphaGo’s victory was a few years ahead of schedule based on reported performance, but it should always have been possible to anticipate some improvement beyond the (small team/data/hardware-based) trend based on significant new effort, data, and hardware being thrown at the problem. Whether AlphaGo deviated from the appropriately-adjusted trend isn’t obvious, especially since there isn’t really much effort going into rigorously modeling such trends today. Until that changes and there are regular forecasts made of possible ranges of future progress in different domains given different effort/data/hardware levels, “breakthroughs” may seem more surprising than they really should be.
Lessons re: the nature/pace of AI progress in general
The above suggested that we should at least slightly downgrade our extent of surprise/impressedness regarding the AlphaGo victory. However, I still think it is an impressive achievement, even if wasn’t sudden or shocking. Rather, it is yet another sign of all that has already been achieved in AI, and the power of various methods that are being used.
Neural networks play a key role in AlphaGo. That they are applicable to Go isn’t all that surprising, since they’re broadly applicable – a neural network can in principle represent any computable function. But AlphaGo is another sign that they can not only in principle learn to do a wide range of things, but can do so relatively efficiently, i.e. in a human-relevant amount of time, with the hardware that currently exists, on tasks that are often considered to require significant human intelligence. Moreover, they are able to not just do things commonly (and sometimes dismissively) referred to as “pattern recognition” but also represent high level strategies, like those required to excel at Go. This scalability of neural networks (not just to larger data/computational power but to different domains of cognition) is indicated by not just AlphaGo but various other recent AI results. Indeed, even without MCTS, AlphaGo outperformed all existing systems with MCTS, one of the most interesting findings here and one that has been omitted in some analyses of AlphaGo’s victory. AlphaGo is not alone in showing the potential of neural networks to do things generally agreed upon as being “cognitive” – another very recent paper showed neural networks being applied to other planning tasks.
It’s too soon to say whether AlphaGo can be trained just with self-play, or how much of its performance can be traced to the specific training regimen used. But the hardware scaling studies shown in the paper give us additional reason to think that AI can, with sufficient hardware and data, extend significantly beyond human performance. We already knew this from recent ImageNet computer vision results, where human level performance in some benchmarks has been exceeded, along with some measures of speech recognition and many other results. But AlphaGo is an important reminder that “human-level” is not a magical stopping point for intelligence, and that many existing AI techniques are highly scalable, perhaps especially the growing range of techniques researchers at DeepMind and elsewhere have branded as “deep reinforcement learning.”
I’ve also looked in some detail at progress in Atari AI (perhaps a topic for a future blog post), which has led me to similar conclusion: there was only a very short period in time when Atari AI was roughly in the ballpark of human performance, namely around 2014/2015. Now, median human-scaled performance across games is well above 100%, and the mean is much higher – around 600%. There is only a small number of games in which human-level performance has not yet been shown, and in those where it has, super-human performance has usually followed soon after.
In addition to lessons we may draw from AlphaGo’s victory, there are also some questions raised: e.g. what areas of cognition are not amenable to substantial gains in performance achieved through huge computational resources, data, and expert effort? Theories of what’s easy/hard to automate in the economy abound, but rarely do such theories look beyond the superficial question of where AI progress has already been, to the harder question of what we can say in a principled way about easy/hard cognitive problems in general. In addition, there’s the empirical question of which domains there exist sufficient data/computational resources for (super)human level performance in already, or where there soon will be. For example, should we be surprised if Google soon announced that they have a highly linguistically competent personal assistant, trained in part from their massive datasets and with the latest deep (reinforcement) learning techniques? That’s difficult to answer. These and other questions, including long-term AI safety, in my view, call for more rigorous modeling of AI progress across cognitive/economically-relevant domains.
The Lee Sedol match and other future updates
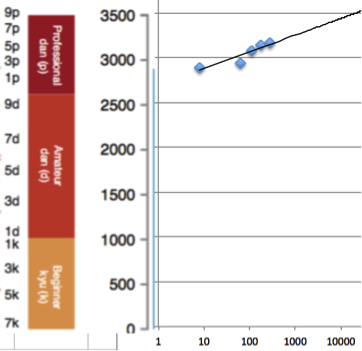
In the spirit of model-based extrapolation versus intuitive judgments, I made the above figure using the apparent relationship between GPUs and Elo scores in DeepMind’s scaling study (the graph for CPUs looks similar). I extended the trend out to the rough equivalent of 5 minutes of calculation per move, closer to what will be the case in the Lee Sedol match, as opposed to 2 seconds per move as used in the scaling study. This assumes returns to hardware remain about the same at higher levels of skill (which may not be the case, but as indicated in the technology forecasting literature, naive models often beat no models!). This projection indicates that just scaling up hardware/giving AlphaGo more time to think may be sufficient to reach Lee Sedol-like performance (in the upper right, around 3500). However, this is hardly the approach DeepMind is banking on – in addition to more time for AlphaGo to compute the best move than in their scaling study, there will also be significant algorithmic improvements. Hassabis said at AAAI that they are working on improving AlphaGo in every way. Indeed, they’ve hired Fan Hui to help them. These and other considerations such as Hassabis’s apparent confidence (and he has access to relevant data, like current-AlphaGo’s performance against October-AlphaGo) suggest AlphaGo has a very good chance of beating Lee Sedol. If this happens, we should further update our confidence regarding the scalability of deep reinforcement learning, and perhaps of value/policy networks. If not, it may suggest some aspects of cognition are less amenable to deep reinforcement learning and hardware scaling than we thought. Likewise if self-play is ever shown to be sufficient to enable comparable performance, and/or if value/policy networks enable superhuman performance in other games, we should similarly increase our assessment of the scalability and generality of modern AI techniques.
One final note on the question of “general AI.” As noted earlier, Hassabis emphasized the purported generality of value/policy networks over the purported narrowness of Deep Blue’s design. While the truth is more complex than this dichotomy (remember, AlphaGo used some hand-crafted features for MCTS), there is still the point above about the generality of deep reinforcement learning. Since DeepMind’s seminal 2013 paper on Atari, deep reinforcement learning has been applied to a wide range of tasks in real-world robotics as well as dialogue. There is reason to think that these methods are fairly general purpose, given the range of domains to which they have been successfully applied with minimal or no hand-tuning of the algorithms. However, in all the cases discussed here, progress so far has largely been toward demonstrating general approaches for building narrow systemsrather than general approaches for building general systems. Progress toward the former does not entail substantial progress toward the latter. The latter, which requires transfer learning among other elements, has yet to have its Atari/AlphaGo moment, but is an important area to keep an eye on going forward, and may be especially relevant for economic/safety purposes. This suggests that an important element of rigorously modeling AI progress may be formalizing the idea of different levels of generality of operating AI systems (as opposed to the generality of the methods that produce them, though that is also important). This is something I’m interested in possibly investigating more in the future and I’d be curious to hear people’s thoughts on it and the other issues raised above.
This article was originally posted on milesbrundage.com.
About the Future of Life Institute
The Future of Life Institute (FLI) is a global think tank with a team of 20+ full-time staff operating across the US and Europe. FLI has been working to steer the development of transformative technologies towards benefitting life and away from extreme large-scale risks since its founding in 2014. Find out more about our mission or explore our work.
Related content
Other posts about AI, Recent News



