AI Alignment Podcast: Astronomical Future Suffering and Superintelligence with Kaj Sotala

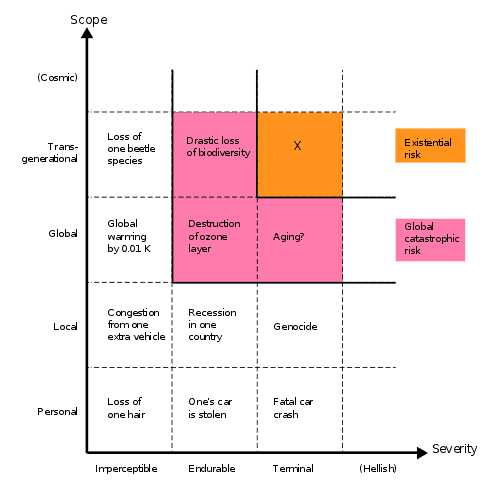
In a classic taxonomy of risks developed by Nick Bostrom (seen below), existential risks are characterized as risks which are both terminal in severity and transgenerational in scope. If we were to maintain the scope of a risk as transgenerational and increase its severity past terminal, what would such a risk look like? What would it mean for a risk to be transgenerational in scope and hellish in severity?
Astronomical Future Suffering and Superintelligence is the second podcast in the new AI Alignment series, hosted by Lucas Perry. For those of you that are new, this series will be covering and exploring the AI alignment problem across a large variety of domains, reflecting the fundamentally interdisciplinary nature of AI alignment. Broadly, we will be having discussions with technical and non-technical researchers across areas such as machine learning, AI safety, governance, coordination, ethics, philosophy, and psychology as they pertain to the project of creating beneficial AI. If this sounds interesting to you, we hope that you will join in the conversations by following us or subscribing to our podcasts on Youtube, SoundCloud, or your preferred podcast site/application.
If you're interested in exploring the interdisciplinary nature of AI alignment, we suggest you take a look here at a preliminary landscape which begins to map this space.
In this podcast, Lucas spoke with Kaj Sotala, an associate researcher at the Foundational Research Institute. He has previously worked for the Machine Intelligence Research Institute, and has publications on AI safety, AI timeline forecasting, and consciousness research.
Topics discussed in this episode include:
- The definition of and a taxonomy of suffering risks
- How superintelligence has special leverage for generating or mitigating suffering risks
- How different moral systems view suffering risks
- What is possible of minds in general and how this plays into suffering risks
- The probability of suffering risks
- What we can do to mitigate suffering risks
Transcript
Lucas: Hi, everyone. Welcome back to the AI Alignment Podcast of the Future of Life Institute. If you are new or just tuning in, this is a new series at FLI where we'll be speaking with a wide variety of technical and nontechnical domain experts regarding the AI alignment problem, also known as the value alignment problem. If you're interested in AI alignment, the Future of Life Institute, existential risks, and similar topics in general, please remember to like and subscribe to us on SoundCloud or your preferred listening platform.
Today, we'll be speaking with Kaj Sotala. Kaj is an associate researcher at the Foundational Research Institute. He has previously worked for the Machine Intelligence Research Institute, and has publications in the areas of AI safety, AI timeline forecasting, and consciousness research. Today, we speak about suffering risks, a class of risks most likely brought about by new technologies, like powerful AI systems that could potentially lead to astronomical amounts of future suffering through accident or technical oversight. In general, we're still working out some minor kinks with our audio recording. The audio here is not perfect, but does improve shortly into the episode. Apologies for any parts that are less than ideal. With that, I give you Kaj.
Lucas: Thanks so much for coming on the podcast, Kaj. It's super great to have you here.
Kaj: Thanks. Glad to be here.
Lucas: Just to jump right into this, could you explain a little bit more about your background and how you became interested in suffering risks, and what you're up to at the Foundational Research Institute?
Kaj: Right. I became interested in all of this stuff about AI and existential risks way back in high school when I was surfing the internet until I somehow ran across the Wikipedia article for the technological singularity. After that, I ended up reading Eliezer Yudkowksy's writings, and writings by other people. At one point, I worked for the Machine Intelligence Research Institute, immersed in doing strategic research, did some papers on predicting AI that makes a lot of sense together with Stuart Armstrong of the Future of Humanity Institute. Eventually, MIRI's focus on research shifted more into more technical and mathematical research, which wasn't exactly my strength, and at that point we parted ways and I went back to finish my master's degree in computer science. Then after I graduated, I ended up being contacted by the Foundational Research Institute, who had noticed my writings on these topics.
Lucas: Could you just unpack a little bit more about what the Foundational Research Institute is trying to do, or how they exist in the effective altruism space, and what the mission is and how they're differentiated from other organizations?
Kaj: They are the research arm of the Effective Altruism Foundation in the German-speaking area. The Foundational Research Institute's official tagline is, "We explain how humanity can best reduce suffering." The general idea is that a lot of people have this intuition that if you are trying to improve the world, then there is a special significance on reducing suffering, and especially about outcomes involving extreme suffering have some particular moral priority, that we should be looking at how to prevent those. In general, the FRI has been looking at things like the long-term future and how to best reduce suffering at long-term scales, including things like AI and emerging technologies in general.
Lucas: Right, cool. At least my understanding is, and you can correct me on this, is that the way that FRI sort of leverages what it does is that ... Within the effective altruism community, suffering risks are very large in scope, but it's also a topic which is very neglected, but also low in probability. Has FRI really taken this up due to that framing, due to its neglectedness within the effective altruism community?
Kaj: I wouldn't say that the decision to take it up was necessarily an explicit result of looking at those considerations, but in a sense, the neglectedness thing is definitely a factor, in that basically no one else seems to be looking at suffering risks. So far, most of the discussion about risks from AI and that kind of thing has been focused on risks of extinction, and there have been people within FRI who feel that risks of extreme suffering might actually be very plausible, and may be even more probable than risks of extinction. But of course, that depends on a lot of assumptions.
Lucas: Okay. I guess just to move foreward here and jump into it, given FRI's mission and what you guys are all about, what is a suffering risk, and how has this led you to this paper?
Kaj: The definition that we have for suffering risks is that a suffering risk is a risk where an adverse outcome would bring about severe suffering on an astronomical scale, so vastly exceeding all suffering that has existed on earth so far. The general thought here is that if we look at the history of earth, then we can probably all agree that there have been a lot of really horrible events that have happened, and enormous amounts of suffering. If you look at something like the Holocaust or various other terrible events that have happened throughout history, there is an intuition that we should make certain that nothing this bad happens ever again. But then if we start looking at what might happen if humanity, for instance, colonizes space one day, then if current trends might continue, then you might think that there is no reason why such terrible events wouldn't just repeat themselves over and over again as we expand into space.
That's sort of one of the motivations here. The paper we wrote is specifically focused on the relation between suffering risks and superintelligence, because like I mentioned, there has been a lot of discussion about superintelligence possibly causing extinction, but there might also be ways by which superintelligence might either cause suffering risks, for instance in the form of some sort of uncontrolled AI, or alternatively, if we could develop some kind of AI that was aligned with humanity's values, then that AI might actually be able to prevent all of those suffering risks from ever being realized.
Lucas: Right. I guess just, if we're really coming at this from a view of suffering-focused ethics, where we're really committed to mitigating suffering, even if we just view sort of the history of suffering and take a step back, like, for 500 million years, evolution had to play out to reach human civilization, and even just in there, there's just a massive amount of suffering, in animals evolving and playing out and having to fight and die and suffer in the ancestral environment. Then one day we get to humans, and in the evolution of life on earth, we create civilization and technologies. In seems, and you give some different sorts of plausible reasons why, that either for ignorance or efficiency or, maybe less likely, malevolence, we use these technologies to get things that we want, and these technologies seem to create tons of suffering.
In our history so far, we've had things ... Like you mentioned, the invention of the ship has helped lead to slavery, which created an immense amount of suffering. Modern industry has led to factory farming, which has created an immense amount of suffering. As we move foreward and we create artificial intelligence systems and potentially even one day superintelligence, we're really able to mold the world more so into a more extreme state, where we're able to optimize it much harder. In that optimization process, it seems the core of the problem lies, is that when you're taking things to the next level and really changing the fabric of everything in a very deep and real way, that suffering can really come about. The core of the problem seems that, when technology is used to fix certain sorts of problems, like that we want more meat, or that we need more human labor for agriculture and stuff, that in optimizing for those things we just create immense amounts of suffering. Does that seem to be the case?
Kaj: Yeah. That sounds like a reasonable characterization.
Lucas: Superintelligence seems to be one of these technologies which is particularly in a good position to be worried it creating suffering risks. What are the characteristics, properties, and attributes of computing and artificial intelligence and artificial superintelligence that gives it this special leverage in being risky for creating suffering risks?
Kaj: There's obviously the thing about superintelligence potentially, as you mentioned, being able to really reshape the world at a massive scale. But if we compare what is the difference between a superintelligence that is capable of reshaping the world at a massive scale versus humans doing the same using technology ... A few specific scenarios that we have been looking at in the paper is, for instance, if we compare to a human civilization, then a major force in human civilizations is that most humans are relatively empathic, and while we can see that humans are willing to cause others serious suffering if that is the only, or maybe even the easiest way of achieving their goals, a lot of humans still want to avoid unnecessary suffering. For instance, currently we see factory farming, but we also see a lot of humans being concerned about factory farming practices, a lot of people working really hard to reform things so that there would be less animal suffering.
But if we look at, then, artificial intelligence, which was running things, then if it is not properly aligned with our values, and in particular if it does not have something that would correspond to a sense of empathy, and it's just actually just doing whatever things maximize its goals, and its goals do not include prevention of suffering, then it might do things like building some kind of worker robots or subroutines that are optimized for achieving whatever goals it has. But if it turns out that the most effective way of making them do things is to build them in such a way that they suffer, then in that case there might be an enormous amount of suffering agents with no kind of force that was trying to prevent their existence or trying to reduce the amount of suffering in the world.
Another scenario is the possibility of mind-crime. This is discussed in Bostrom's Superintelligence briefly. The main idea here is that if the superintelligence creates simulations of sentient minds, for instance for scientific purposes or the purposes of maybe blackmailing some other agent in the world by torturing a lot of minds in those simulations, AI might create simulations of human beings that were detailed enough to be conscious. Then you mentioned earlier the thing about evolution already have created a lot of suffering. If the AI were similarly to simulate evolution or simulate human societies, again without caring about the amount of suffering within those simulations, then that could again cause vast amounts of suffering.
Lucas: I definitely want to dive into all of these specific points with you as they come up later in the paper, and we can really get into and explore them. But so, really just to take a step back and understand what superintelligence is and the different sorts of attributes that it has, and how it's different than human beings and how it can lead to suffering risk. For example, there seems to be multiple aspects here where we have to understand superintelligence as a general intelligence running at digital timescales rather than biological timescales.
It also has the ability to copy itself, and rapidly write and deploy new software. Human beings have to spend a lot of time, like, learning and conditioning themselves to change the software on their brains, but due to the properties and features of computers and machine intelligence, it seems like copies could be made for very, very cheap, it could be done very quickly, they would be running at digital timescales rather than biological timescales.
Then it seems there's the whole question about value-aligning the actions and goals of this software and these systems and this intelligence, and how in the value alignment process there might be technical issues where, due to difficulties in AI safety and value alignment efforts, we're not able to specify or really capture what we value. That might lead to scenarios like you were talking about, where there would be something like mind-crime, or suffering subroutines which would exist due to their functional usefulness or epistemic usefulness. Is there anything else there that you would like to add and unpack about why superintelligence specifically has a lot of leverage for leading to suffering risks?
Kaj: Yeah. I think you covered most of the things. I think the thing that they are all leading to that I just want to specifically highlight is the possibility of the superintelligence actually establishing what Nick Bostrom calls a singleton, basically establishing itself as a single leading force that basically controls the world. I guess in one sense you could talk about singletons in general and their impact on suffering risks, rather than superintelligence specifically, but at this time it does not seem very plausible, or at least I cannot foresee, very many other paths to a singleton other than superintelligence. That was a part of why we were focusing on superintelligence in particular.
Lucas: Okay, cool. Just to get back to the overall structure of your paper, what are the conditions here that you cover that must be met in order for s-risks to merit our attention? Why should we care about s-risks? Then what are all the different sorts of arguments that you're making and covering in this paper?
Kaj: Well, basically, in order for any risk, suffering risks included, to merit work on them, they should meet three conditions. The first is that the outcome of the risk should be sufficiently severe to actually merit attention. Second, the risk must have some reasonable probability of actually being realized. Third, there must be some way for risk avoidance work to actually reduce either the probability or the severity of the adverse outcome. If something is going to happen for certain and it's very bad, then if we cannot influence it, then obviously we cannot influence it, and there's no point in working on it. Similarly, if some risk is very implausible, then it might not be the best use of resources. Also, if it's very probable but wouldn't cause a lot of damage, then it might be better to focus on risks which would actually cause more damage.
Lucas: Right. I guess just some specific examples here real quick. The differences here are essentially between, like, the death of the universe, if we couldn't do anything about it, we would just kind of have to deal with that, then sort of like a Pascal mugging situation, where a stranger just walks up to you on the street and says, "Give me a million dollars or I will simulate 10 to the 40 conscious minds suffering until the universe dies." The likelihood of that is just so low that you wouldn't have to deal with it. Then it seems like the last scenario would be, like, you know that you're going to lose a hair next week, and that's just sort of like an imperceptible risk that doesn't matter, but that has very high probability. Then getting into the meat of the paper, what are the arguments here that you make regarding suffering risks? Does suffering risk meet these criteria for why it merits attention?
Kaj: Basically, the paper is roughly structured around those three criteria that we just discussed. We basically start by talking about what the s-risks are, and then we seek to establish that if they were realized, they would indeed be bad enough to merit our attention. In particular, we argue that many value systems would consider some classes of suffering risks to be as bad or worse than extinction. Also, we cover some suffering risks which are somewhat less severe that extinction, but still, according to many value systems, very bad.
Then we move on to look at the probability of the suffering risks to see whether it is actually plausible that they will be realized. We survey what might happen if nobody builds a superintelligence, or maybe more specifically, if there is no singleton that could prevent suffering risks that might be realized sort of naturally, in the absence of a singleton.
We also look at, okay, if we do have a superintelligence or a singleton, what suffering risks might that cause? Finally, we look at the last question, of the tractability. Can we actually do anything about these suffering risks? There we also have several suggestions of what we think would be the kind of work that would actually be useful in either reducing the risk or the severity of suffering risks.
Lucas: Awesome. Let's go ahead and move sequentially through these arguments and points which you develop in the paper. Let's start off here by just trying to understand suffering risk just a little bit more. Can you unpack the taxonomy of suffering risks that you develop here?
Kaj: Yes. We've got three possible outcomes of suffering risks. Technically, a risk is something that may or may not happen, so three specific outcomes of what might happen. The three outcomes, I'll just briefly give their names and then unpack them. We've got what we call astronomical suffering outcomes, net suffering outcomes, and pan-generational net suffering outcomes.
I'll start with the net suffering outcome. Here, the idea is that if we are talking about a risk which might be of a comparable severity as risks of extinction, then one way you could get that is if, for instance, we look from the viewpoint of something like classical utilitarianism. You have three sorts of people. You have people who have a predominantly happy life, you have people who never exist or have a neutral life, and you have people who have a predominantly unhappy life. As a simplified moral calculus, you just assign the people with happy lives a plus-one, and you assign the people with unhappy lives a minus-one. Then according to this very simplified moral system, then you would see that if we have more unhappy lives than there are happy lives, then technically this would be worse than there not existing any lives at all.
That is what we call a net suffering outcome. In other words, at some point in time there are more people experiencing lives that are more unhappy than happy, and there are people experiencing lives which are the opposite. Now, if you have a world where most people are unhappy, then if you're optimistic you might think that, okay, it is bad, but it is not necessarily worse than extinction, because if you look ahead in time, then maybe the world will go on and conditions will improve, and then after a while most people actually live happy lives, so maybe things will get better. We define an alternative scenario in which we just assume that things actually won't get better, and if you sum over all of the lives that will exist throughout history, most of them still end up being unhappy. Then that would be what we call a pan-generational net suffering outcome. When summed over all the people that will ever live, there are more people experiencing lives filled predominantly with suffering than there are people experiencing lives filled predominantly with happiness.
You could also have what we call astronomical suffering outcomes, which is just that at some point in time there's some fraction of the population which experiences terrible suffering, and the amount of suffering here is enough to constitute an astronomical amount that overcomes all the suffering in earth's history. Here we are not making the assumption that the world would be mainly filled with these kinds of people. Maybe you have one galaxy worth of people in terrible pain, and 500 galaxy's worth of happy people. According to some value systems, that would not be worse than extinction, but probably all value systems would still agree that even if this wasn't worse than extinction, it would still be something that would be very much worth avoiding. Those are the three outcomes that we discuss here.
Lucas: Traditionally, the sort of far-future concerned community has mainly only been thinking about existential risks. Do you view this taxonomy and suffering risks in general as being a subset of existential risks? Or how do you view it in relation to what we traditionally view as existential risks?
Kaj: If we look at Bostrom's original definition for an existential risk, the definition was that it is a risk where an adverse outcome would either annihilate earth-originating intelligent life, or permanently and drastically curtail its potential. Here it's a little vague on how exactly you should interpret phrases like "permanently and drastically curtain our potential." You could take the view that suffering risks are a subset of existential risks if you view our potential as being something like the realization of a civilization full of happy people, where nobody ever needs to suffer. In that sense, it would be a subset of existential risks.
It is most obvious with the net suffering outcomes. It seems pretty plausible that most people experiencing suffering would not be the realization of our full potential. Then if you look at something like near-astronomical suffering outcomes, where you might only have a small fraction of the population experiencing suffering, then that, depending on exactly how large the fraction, then you might maybe not count it as a subset of existential risks, and maybe something more comparable to catastrophic risks, which have usually been defined on the order of a few million people dying. Obviously, the astronomical suffering outcomes are worse than catastrophic risks, but maybe something more comparable to catastrophic risks than existential risks.
Lucas: Given the taxonomy that you've gone ahead and unpacked, what are the different sorts of perspectives that different value systems on earth have of suffering risks? Just unpack a little bit what the general value systems are that human beings are running in their brains.
Kaj: If we look at ethics, philosophers have proposed a variety of different value systems and ethical theories. If we just look at the few of the main ones, then something like classical utilitarianism, where you basically view worlds as good based on what is the balance of happiness minus suffering. Then if you look at what would be the view of classical utilitarianism on suffering risks, classical utilitarianism would find these worst kinds of outcomes, net suffering outcomes as worse than extinction. But they might find astronomical suffering outcomes as an acceptable cost of having even more happy people. They might look at that, one galaxy full of suffering people, and think that, "Well, we have 200 galaxies full of happy people, so it's not optimal to have those suffering people, but we have even more happy people, so that's okay.
A lot of moral theories are not necessarily explicitly utilitarian, or they might have a lot of different components and so on, but a lot of them still include some kind of aggregative component, meaning that they still have some element of, for instance, looking at suffering and saying that other things being equal, it's worse to have more suffering. This would, again, find suffering risks something to avoid, depending on exactly how they weight things and how they value things. Then it will depend on those specific weightings, on whether they find suffering risks as worse than extinction or not.
Also worth noting that even if the theories wouldn't necessarily talk about suffering exactly, they might still talk about something like preference satisfaction, whether people are having their preferences satisfied, some broader notion of human flourishing, and so on. In scenarios where there is a lot of suffering, probably a lot of these things that these theories consider valuable would be missing. For instance, if there is a lot of suffering and people cannot escape that suffering, then probably there are lots of people whose preferences are not being satisfied, if they would prefer not to suffer and they would prefer to escape the suffering.
Then there are little kinds of rights-based theories, which don't necessarily have this aggregative component directly, but are more focused on thinking in terms of rights, which might not be summed together directly, but depending on how these theories would frame rights ... For instance, some theories might hold that people or animals have a right to avoid unnecessary suffering, or these kinds of theories might consider suffering indirectly bad if the suffering was created by some condition which violated people's rights. Again, for instance, if people have a right for meaningful autonomy and they are in circumstances in which they cannot escape their suffering, then you might hold that their right for a meaningful autonomy has been violated.
A bunch of moral intuitions, which might fit a number of moral theories and which might particularly prioritize the prevention of suffering in particular. I mentioned that classical utilitarianism basically weights extreme happiness and extreme suffering the same, so it will be willing to accept a large amount of suffering if you could produce a lot of, even more, happiness that way. But for instance, there have been moral theories like prioritarianism proposed, which might make a different judgment.
Prioritarianism is the position that the worse off an individual is, the more morally valuable it is to make that individual better off. If one person is living in hellish conditions and another is well-off, then if you could sort of give either one of them five points of extra happiness, then it would be much more morally pressing to help the person who was in more pain. This seems like an intuition that I think a lot of people share, and if you had something like some kind of an astronomical prioritarianism that considered all across the universe and prioritized improving the worst ones off, then that might push in the direction of mainly improving the lives of those that would be worst off and avoiding suffering risks.
Then there are a few other sort of suffering-focused intuitions. A lot of moral intuitions have this intuition that it's more important to make people happy than it is to create new happy people. This one is rather controversial, and a lot of EA circles seem to reject this intuition. It's true that there are some strong arguments against it, but at the other hand, rejecting it also seems to lead to some paradoxical conclusions. Here, the idea behind this intuition is that the most important thing is helping existing people. If we think about, for instance, colonizing the universe, someone might argue that if we colonized the universe, then that will create lots of new lives who will be happy, and that will be a good thing, even if this comes at the cost of create a vast number of unhappy lives as well. But if you take the view that the important thing is just making existing lives happy and we don't have any special obligation to create new lives that are happy, then it also becomes questionable whether it is worth the risk of creating a lot of suffering for the sake of just creating happy people.
Also, there is an intuition of, torture-level suffering cannot be counterbalanced. Again, there are a bunch of good arguments against this one. There's a nice article by Toby Ord called "Why I Am Not a Negative Utilitarian," which argues against versions of this thesis. But at the same time, there does seem to be something that has a lot of intuitive weight for a lot of people. Here the idea is that there are some kinds of suffering so intense and immense that you cannot really justify that with any amount of happiness. David Pearce has expressed this well in his quote where he says, "No amount of happiness or fun enjoyed by some organisms can notionally justify the indescribable horrors of Auschwitz." Here we must think that, okay, if we go out and colonize the universe, and then we know that colonizing the universe is going to create some equivalent event as what went on in Auschwitz and at other genocides across the world, then no amount of happiness that we create that way will be worth that terrible terror that would probably also be created if there was nothing to stop it.
Finally, there's an intuition of happiness being the absence of suffering, which is the sort of an intuition that is present in Epicureanism and some non-Western traditions, such as Buddhism, where happiness is thought as being the absence of suffering. The idea is that when we are not experiencing any pleasure, we begin to crave pleasure, and it is this craving that constitutes suffering. Under this view, happiness does not have intrinsic value, but rather it has instrumental value in taking our focus away from suffering and helping us avoid suffering that way. Under that view, creating additional happiness doesn't have any intrinsic value if that creation does not help us avoid suffering.
I mentioned here a few of these suffering-focused intuitions. Now, in presenting these, my intent is not to say that there would not also exist counter-intuitions. There are a lot of reasonable people who disagree with these intuitions. But the general point that I'm just expressing is that regardless of which specific moral system we are talking about, these are the kinds of intuitions that a lot of people find plausible, and which could reasonably fit in a lot of different moral theories and value systems, and probably a lot of value systems contain some version of these.
Lucas: Right. It seems like the general idea is just that whether you're committed to some sort of form of consequentialism or deontology or virtue ethics, or perhaps something that's even potentially theological, there are lots of aggregative or non-aggregative, or virtue-based or rights-based reasons for why we should care about suffering risks. Now, it seems to me that potentially here probably what's most important, or where these different normative and meta-ethical views matter in their differences, is in how you might proceed forward and engage in AI research and in deploying and instantiating AGI and superintelligence, given your commitment more or less to a view which takes the aggregate, versus one which does not. Like you said, if you take a classical utilitarian view, then one might be more biased towards risking suffering risks given that there might still be some high probability of there being many galaxies which end up having very net positive experiences, and then maybe one where there might be some astronomical suffering. How do you view the importance of resolving meta-ethical and normative ethical disputes in order to figure out how to move foreward in mitigating suffering risks?
Kaj: The general problem here, I guess you might say, is that there exist trade-offs between suffering risks and existential risks. If we had a scenario where some advanced general technology or something different might constitute an existential risk to the world, then someone might think about trying to solve that with AGI, which might have some probability of not actually working properly and not actually being value-aligned. But someone might think that, "Well, if we do not activate this AGI, then we are all going to die anyway, because of this other existential risk, so might as well activate it." But then if there is a sizable probability of the AGI actually causing a suffering risk, as opposed to just an existential risk, then that might be a bad idea. As you mentioned, the different value systems will make different evaluations about these trade-offs.
In general, I'm personally pretty skeptical about actually resolving ethics, or solving it in a way that would be satisfactory to everyone. I expect there a lot of the differences between meta-ethical views could just be based on moral intuitions that may come down to factors like genetics or the environment where you grew up, or whatever, and which are not actually very factual in nature. Someone might just think that some specific, for instance, suffering-focused intuition was very important, and someone else might think that actually that intuition makes no sense at all.
The general approach, I would hope, that people take is that if we have decisions where we have to choose between an increased risk of extinction or an increased risk of astronomical suffering, then it would be better if people from all ethical and value systems would together try to cooperate. Rather than risk conflict between value systems, a better alternative would be to attempt to identify interventions which did not involve trading off one risk for another. If there were interventions that reduced the risk of extinction without increasing the risk of astronomical suffering, or decreased the risk of astronomical suffering without increasing the risk of extinction, or decreased both risks, then it would be in everyone's interest if we could agree, okay, whatever our moral differences, let's just jointly focus on these classes of interventions that actually seem to be a net positive in at least one person's value system.
Lucas: Like you identify in the paper, it seems like the hard part is when you have trade-offs.
Kaj: Yes.
Lucas: Given this, given that most value systems should care about suffering risks, now that we've established the taxonomy and understanding of what suffering risks are, discuss a little bit about how likely suffering risks are relative to existential risks and other sorts of risks that we encounter.
Kaj: As I mentioned earlier, these depend somewhat on, are we assuming a superintelligence or a singleton or not? Just briefly looking at the case where we do not assume a superintelligence or singleton, we can see that in history so far there does not seem to be any consistent trend towards reduced suffering, if you look at a global scale. For instance, the advances in seafaring enabled the transatlantic slave trade, and similarly, advances in factory farming practices have enabled large amounts of animals being kept in terrible conditions. You might plausibly think that the net balance of suffering and happiness caused by the human species right now was actually negative due to all of the factory farmed animals, although it is another controversial point. Generally, you can see that if we just extrapolated the trends so far to the future, then we might see that, okay, there isn't any obvious sign of there being less suffering in the world as technology develops, so it seems like a reasonable assumption, although not the only possible assumption, that as technology advances, it will also continue to enable more suffering, and future civilizations might also have large amounts of suffering.
If we look at the outcomes where we do have a superintelligence or a singleton running the world, here things get, if possible, even more speculative. In the beginning, we can at least think of some plausible-seeming scenarios in which a superintelligence might end up causing large amounts of suffering, such as building suffering subroutines. It might create mind-crime. It might also try to create some kind of optimal human society, but some sort of the value learning or value extrapolation process might be what some people might consider incorrect in such a way that the resulting society would also have enormous amounts of suffering. While it's impossible to really give any probability estimates on exactly how plausible is a suffering risk, and depends on a lot of your assumptions, it does at least seem like a plausible thing to happen with a reasonable probability.
Lucas: Right. It seems that just technology, like intrinsic to what technology is, is it's giving you more leverage and control over manipulating and shaping the world. As you gain more causal efficacy over the world and other sentient beings, it seems kind of obviously that yeah, you also gain more ability to cause suffering, because your causal efficacy is increasing. It seems very important here to isolate the causal factors in people and just in the universe in general, which lead to this great amount of suffering. Technology is a tool, a powerful tool, and it keeps getting more powerful. The hand by which the tool is guided is ethics.
But it doesn't seem that historically, and in the case of superintelligence as well, that primarily the vast amounts of suffering that have been caused are because of failures in ethics. I mean, surely there has been large failures in ethics, but evolution is just an optimization process which leads to vast amounts of suffering. There could be similar evolutionary dynamics in superintelligence which lead to great amounts of suffering. It seems like issues with factory farming and slavery are not due to some sort of intrinsic malevolence in people, but rather it seems sort of like an ethical blind spot and apathy, and also a solution to an optimization problem where we get meat more efficiently, and we get human labor more efficiently. It seems like we can apply these lessons to superintelligence. It seems like it's not likely that superintelligence will produce astronomical amounts of suffering due to malevolence.
Kaj: Right.
Lucas: Or like, intentional malevolence. It seems there might be, like, a value alignment problem or mis-specification, or just generally in optimizing that there might be certain things, like mind-crime or suffering subroutines, which are functionally very useful or epistemically very useful, and in their efficiency for making manifest other goals, they perhaps astronomically violate other values which might be more foundational, such as the mitigation of suffering and the promotion of wellbeing across all sentient beings. Does that make sense?
Kaj: Yeah. I think one way I might phrase that is that we should expect there to be less suffering if the incentives created by the future world for whatever agents are acting there happen to align with doing the kinds of things that cause less suffering. And vice versa, if the incentives just happen to align with actions that cause agents great personal benefit, or at least the agents that are in power great personal benefit while suffering actually being the inevitable consequence of following those incentives, then you would expect to see a lot of suffering. As you mentioned, with evolution, there isn't even an actual agent to speak of, but just sort of in free-running optimization process, and the solutions which that optimization process has happened to hit on have just happened to involve large amounts of suffering. There is a major risk of a lot of suffering being created by the kinds of processes that are actually not actively malevolent, and some of which might actually care about preventing suffering, but then just the incentives are such that they end up creating suffering anyway.
Lucas: Yeah. I guess what I find very fascinating and even scary here is that there are open questions regarding the philosophy of mind and computation and intelligence, where we can understand pain and anger and pleasure and happiness and all of these hedonic valences within consciousness as, at very minimum, being correlated with cognitive states which are functionally useful. These hedonic valences are informationally sensitive, and so they give us information about the world, and they sort of provide a functional use. You discuss here how it seems like anger and pain and suffering and happiness and joy, all of these seem to be functional attributes of the mind that evolution has optimized for, and they may or may not be the ultimate solution or the best solution, but they are good solutions to avoiding things which may or may not be bad for us, and promoting behaviors which lead to social cohesion and group coordination.
I think there's a really deep and fundamental question here about whether or not minds in principle can be created to have informationally-sensitive, hedonically-positive states. Is David Pearce puts it, there's sort of an open question about, I think, whether or not minds in principle can be created to function on informationally-sensitive gradients of bliss. If that ends up being false, and that anger and suffering end up providing some really fundamental functional and epistemic place in minds in general, then I think that that's just a hugely fundamental problem about the future and the kinds of minds that we should or should not create.
Kaj: Yeah, definitely. Of course, if we are talking about avoiding outcomes with extreme suffering, perhaps you might have scenarios where it is unavoidable to have some limited amount of suffering, but you could still create minds that were predominantly happy, and maybe they got angry and upset at times, but that would be a relatively limited amount of suffering that they experienced. You can definitely already see that there are some people alive who just seem to be constantly happy, and don't seem to suffer very much at all. But of course, there is also the factor that if you are running on so-called negative emotions, and you do have anger and that kind of thing, then you are, again, probably more likely to react to situations in ways which might cause more suffering in others, as well as yourself. If we could create the kinds of minds that only had a limited amount of suffering from negative emotions, then you could [inaudible 00:49:27] that they happened to experience a bit of anger and lash out at others probably still wouldn't be very bad, since other minds still would only experience the limited amount of suffering.
Of course, this gets to various philosophy of mind questions, as you mentioned. Personally, I tend to lean towards the views that it is possible to disentangle pain and suffering from each other. For instance, various Buddhist meditative practices are actually making people capable of experiencing pain without experiencing suffering. You might also have theories of mind which hold that the sort of higher-level theories of suffering are maybe too parochial. Like, Brian Tomasik has this view that maybe just anything that is some kind of negative feedback constitutes some level of suffering. Then it might be impossible to have systems which experienced any kind of negative feedback without also experiencing suffering. I'm personally more optimistic about that, but I do not know if I have any good, philosophically-rigorous reasons for being more optimistic, other than, well, that seems intuitively more plausible to me.
Lucas: Just to jump in here, just to add a point of clarification. It might seem sort of confusing how one might be experiencing pain without suffering.
Kaj: Right.
Lucas: Do you want to go ahead and unpack, then, the Buddhist concept of dukkha, and what pain without suffering really means, and how this might offer an existence proof for the nature of what is possible in minds?
Kaj: Maybe instead of looking at the Buddhist theories, which I expect some of the listeners to be somewhat skeptical about, it might be more useful to look at the term from medicine, pain asymbolia, also called pain dissociation. This is a known state which sometimes result from things like injury to the brain or certain pain medication, where people who have pain asymbolia report that they still experience pain, recognize the sensation of pain, but they do not actually experience it as aversive or something that would cause them suffering.
One way that I have usually expressed this is that pain is an attention signal, and pain is something that brings some sort of specific experience into your consciousness so that you become aware of it, and suffering is when you do not actually want to be aware of that painful sensation. For instance, you might have some physical pain, and then you might prefer not to be aware of that physical pain. But then even if we look at people in relatively normal conditions who do not have this pain asymbolia, then we can see that even people in relatively normal conditions may sometimes find the pain more acceptable. For some people who are, for instance, doing physical exercise, the pain may actually feel welcome, and a sign that they are actually pushing themselves to their limit, and feel somewhat enjoyable rather than being something aversive.
Similarly for, for instance, emotional pain. Maybe the pain might be some, like, mental image of something that you have lost forcing itself into your consciousness and making you very aware of the fact that you have lost this, and then the suffering arises if you think that you do not want to be aware of this thing you have lost. You do not want to be aware of the fact that you have indeed lost it and you will never experience it again.
Lucas: I guess just to sort of summarize this before we move on, it seems that there is sort of the mind stream, and within the mind stream, there are contents of consciousness which arise, and they have varying hedonic valences. Suffering is really produced when one is completely identified and wrapped up in some feeling tone of negative or positive hedonic valence, and is either feeling aversion or clinging or grasping to this feeling tone which they are identified with. The mere act of knowing or seeing the feeling tone of positive or negative valence creates sort of a cessation of the clinging and aversion, which completely changes the character of the experience and takes away this suffering aspect, but the pain content is still there. And so I guess this just sort of probably enters fairly esoteric territory about what is potentially possible with minds, but it seems important for the deep future when considering what is in principle possible of minds and superintelligence, and how that may or may not lead to suffering risks.
Kaj: What you described would be the sort of Buddhist version of this. I do tend to find that very plausible personally, both in light of some of my own experiences with meditative techniques, and clearly noticing that as a result of those kinds of practices, then on some days I might have the same amount of pain as I've had always before, but clearly the amount of suffering associated with that pain is considerably reduced, and also ... well, I'm far from the only one who reports these kinds of experiences. This kind of model seems plausible to me, but of course, I cannot know it for certain.
Lucas: For sure. That makes sense. Putting aside the possibility of what is intrinsically possible for minds and the different hedonic valences within them and how they may or may not completely inter-tangled with the functionality of minds and the epistemics of minds, one of these possibilities which we've been discussing for superintelligence leading to suffering risks is that we fail in AI alignment. Failure in AI alignment may be due to governance, coordination, or political reasons. It might be caused by an arms race. It might be due to fundamental failures in meta-ethics or normative ethics. Or maybe even most likely it could simply be a technical failure in the inability for human beings to specify our values and to instantiate algorithms in AGI which are sufficiently well-placed to learn human values in a meaningful way and to evolve in a way that is appropriate and can engage new situations. Would you like to unpack and dive into dystopian scenarios created by non-value-aligned incentives in AI, and non-value-aligned AI in general?
Kaj: I already discussed these scenarios a bit before, suffering subroutines, mind-crime, and flawed realization of human values, but maybe one thing that would be worth discussing here a bit is that these kinds of outcomes might be created by a few different pathways. For instance, one kind of pathway is some sort of anthropocentrism. If we have a superintelligence that had been programmed to only care about humans or about minds which were sufficiently human-like by some criteria, then it might be indifferent to the suffering of other minds, including whatever subroutines or sub-minds it created. Or it might be, for instance, indifferent to the suffering experienced by, say, wild animal life in evolutionary simulations it created. Similarly, there is the possibility of indifference in general if we create a superintelligence which is just indifferent to human values, including indifference to reducing or avoiding suffering. Then it might create large numbers of suffering subroutines, it might create large amounts of simulations with sentient minds, and there is also the possibility of extortion.
Assuming the the superintelligence is not actually the only agent or superintelligence in the world ... Maybe either there were several AI projects on earth that gained superintelligence roughly at the same time, or maybe the superintelligence expands into space and eventually encounters another superintelligence. In these kinds of scenarios, if one of the superintelligences cares about suffering but the other one does not, or at least does not care about this as much, then the superintelligence which cared less about suffering might intentionally create mind-crime and instate large numbers of suffering sentient beings in order to intentionally extort the other superintelligence into doing whatever it wants.
One more possibility is libertarianism regarding computation. If we have a superintelligence which has been programmed to just take every current living human being and give each human being some, say, control of an enormous amount of computational resources, and every human is allowed to do literally whatever they want with those resources, then we know that there exist a lot of people who are actively cruel and malicious, and many of those would use those resources to actually create suffering beings that they could torture for their own fun and entertainment.
Finally, if we are looking at these flawed realization kind of scenarios, where a superintelligence is partially value-aligned, but there might be something like, depending on the details of how exactly it is learning human values, and if it is doing some sort of extrapolation from those values, then we know that there have been times in history when circumstances that cause suffering have been defended by appealing to values that currently seem pointless to us, but which were nonetheless a part of the prevailing values at the time. If some value-loading process gave disproportionate weight to historical existing, or incorrectly, extrapolated future values, which endorsed or celebrated cruelty or outright glorified suffering, then we might get a superintelligence which had some sort of creation of suffering actually as an active value in whatever value function it was trying to optimize for.
Lucas: In terms of extortion, I guess just kind of a speculative idea comes to mind. Is there a possibility of a superintelligence acausally extorting other superintelligences if it doesn't care about suffering and expects that to be a possible value, and for there to be other superintelligences nearby?
Kaj: Acausal stuff is the kind of stuff that I'm sufficiently confused about that I don't actually want to say anything about that.
Lucas: That's completely fair. I'm super confused about it too. We've covered a lot of ground here. We've established what s-risks are, we've established a taxonomy for them, we've discussed their probability, their scope. Now, a lot of this probably seems very esoteric and speculative to many of our listeners, so I guess just here in the end I'd like to really drive home how and whether to work on suffering risks. Why is this something that we should be working on now? How do we go about working on it? Why isn't this something that is just so completely esoteric and speculative that it should just be ignored?
Kaj: Let's start by looking at how we could working on avoiding suffering risks, and then when we have some kind of an idea of what the possible ways of doing that are, then that helps us say whether we should be doing those things. One thing that is a sort of a nicely joint interest of both reducing risks of extinction and also reducing risks of astronomical suffering is the kind of general AI value alignment work that is currently being done, classically, by the Machine Intelligence Research Institute and a number of other places. As I've been discussing here, there are ways by which an unaligned AI or one which was partially aligned could cause various suffering outcomes. If we are working on the possibility of actually creating value-aligned AI, then that should ideally also reduce the risk of suffering risks being realized.
In addition to technical work, there are also some societal work, social and political recommendations, which are similar both from the viewpoint of extinction risks and suffering risks. For instance, Nick Bostrom has noted that if we had some sort of conditions of what he calls global turbulence of cooperation and such things breaking down during some crisis, then that could create challenges for creating value-aligned AI. There are things like arms races and so on. If we consider that the avoidance of suffering outcomes is the joint interest of many different value systems, then measures that improve the ability of different value systems to cooperate and shape the world in their desired direction can also help avoid suffering outcomes.
Those were a few things that are sort of the same as with so-called classical AI risk work, but there is also some stuff that might be useful for avoiding negative outcomes in particular. There is the possibility that if we are trying to create an AI which gets all of humanity's values exactly right, then that might be a harder goal than simply creating an AI which attempted to avoid the most terrible and catastrophic outcomes.
You might have things like fail-safe methods, where the idea of the fail-safe methods would be that if AI control fails, the outcome will be as good as it gets under the circumstances. This could be giving the AI the objective of buying more time to more carefully solve goal alignment. Or there could be something like fallback goal functions, where an AI might have some sort of fallback goal that would be a simpler or less ambitious goal that kicks in if things seem to be going badly under some criteria, and which is less likely to result in bad outcomes. Of course, here we have difficulties in selecting what the actual safety criteria would be and making sure that the fallback goal gets triggered under the correct circumstances.
Eliezer Yudkowsky has proposed building potential superintelligences in such a way as to make them widely separated in design space from ones that would cause suffering outcomes. For example, one thing he discussed was that if an AI has some explicit representation of what humans value which it is trying to maximize, then it could only take a small and perhaps accidental change to turn that AI into one that instead maximized the negative of that value and possibly caused enormous suffering that way. One proposal would be to design AIs in such a way that they never explicitly represent complete human values so that the AI never contains enough information to compute the kinds of states of the universe that we would consider worse than death, so you couldn't just flip the sign of the utility function and then end up in a scenario that we would consider worse than death. That kind of a solution would also reduce the risk of suffering being created through another actor that was trying to extort a superintelligence.
Looking more generally at things and suffering risks, we actually already discussed here, there are lots of open questions in philosophy of mind and cognitive science which, if we could answer them, could inform the question of how to avoid suffering risks. If it turns out that you can do something like David Pearce's idea of minds being motivated purely by gradients of wellbeing and not needing to suffer at all, then that might be a great idea, and if we could just come up with such agents and ensure that all of our descendants that go out to colonize the universe are ones that aren't actually capable of experiencing suffering at all, then that would seem to solve a large class of suffering risks.
Of course, this kind of thing could also have more near-term immediate value, like if we figure out how to get human brains into such states where they do not experience much suffering at all, well, obviously that would be hugely valuable already. There might be some interesting research in, for instance, looking even more at all the Buddhist theories and the kinds of cognitive changes that various Buddhist contemplative practices produce in people's brains, and see if we could get any clues from that direction.
Given that these were some ways that we could reduce suffering risks and their probability, then there was the question of whether we should do this. Well, if we look at the initial criteria of when a risk is worth working on, a risk is worth working on if the adverse outcome would be severe and if the risk has some reasonable probability of actually being realized, and it seems like we can come up with interventions that plausible effect either the severity or the probability of a realized outcome. Then a lot of times things seem like they could very plausible either influence these variables or at least help us learn more about whether it is possible to influence those variables.
Especially given that a lot of this work overlaps with the kind of AI alignment research that we would probably want to do anyway for the sake of avoiding extinction, or it overlaps with the kind of work that would regardless be immensely valuable in making currently-existing humans suffer less, in addition to the benefits that these interventions would have on suffering risks themselves, it seems to me like we have a pretty strong case for working on these things.
Lucas: Awesome, yeah. Suffering risks are seemingly neglected in the world. They are tremendous in scope, and they are of comparable probability of existential risks. It seems like there's a lot that we can do here today, even if at first the whole project might seem so far in the future or so esoteric or so speculative that there's nothing that we can do today, whereas really there is.
Kaj: Yeah, exactly.
Lucas: One dimension here that I guess I just want to finish up on that is potentially still a little bit of an open question for me is, in terms of really nailing down the likelihood of suffering risks in, I guess, probability space, especially relative to the space of existential risks. What does the space of suffering risks look like relative to that? Because it seems very clear to me, and perhaps most listeners, that this is clearly tremendous in scale, that it relies on some assumptions about intelligence, philosophy of mind, consciousness and other things which seem to be reasonable assumptions, to sort of get suffering risks off the ground. Given some reasonable assumptions, it seems that there's a clearly large risk. I guess just if we could unpack a little bit more about the probability of them relative to suffering risks. Is it possible to more formally characterize the causes and conditions which lead to x-risks, and then the causes and conditions which lead to suffering risks, and how big these spaces are relative to one another and how easy it is for certain sets of causes and conditions respective to each of the risks to become manifest?
Kaj: That is an excellent question. I am not aware of anyone having done such an analysis for either suffering risks or extinction risks, although there is some work on specific kinds of extinction risks. Seth Baum has been doing some nice fault tree analysis of things that might ... for instance, the probability of nuclear war and the probability of unaligned AI causing some catastrophe.
Lucas: Open questions. I guess just coming away from this conversation, it seems like the essential open questions which we need more people working on and thinking about are the ways in which meta-ethics and normative ethics and disagreements there change the way we optimize the application of resources to either existential risks versus suffering risks, and the kinds of futures which we'd be okay with, and then also sort of pinning down more concretely the specific probability of suffering risks relative to existential risks. Because I mean, in EA and the rationality community, everyone's about maximizing expected value or utility, and it seems to be a value system that people are very set on. And so the probability here, small changes in the probability of suffering risks versus existential risks, probably leads to vastly different, less or more, amounts of value in a variety of different value systems. Then there are tons of questions about what is in principle possible of minds and the kinds of minds that we'll create. Definitely a super interesting field that is really emerging.
Thank you so much for all this foundational work that you and others like your coauthor, Lukas Gloor, have been doing on this paper and the suffering risk field. Is there any other things you'd like to touch on? Any questions or specific things that you feel haven't been sufficiently addressed?
Kaj: I think we have covered everything important. I will probably think of something that I will regret not mentioning five minutes afterwards, but yeah.
Lucas: Yeah, yeah. As always. Where can we check you out? Where can we check out the Foundational Research Institute? How do we follow you guys and stay up to date?
Kaj: Well, if you just Google the Foundational Research Institute or go to foundational-research.org, that's our website. We, like everyone else, also post stuff on a Facebook page, and we have a blog for posting updates. Also, if people want a million different links just about everything conceivable, they will probably get that if they follow my personal Facebook, page, where I do post a lot of stuff in general.
Lucas: Awesome. Yeah, and I'm sure there's tons of stuff, if people want to follow up on this subject, to find on your guys's site, as you guys are primarily the people who are working and thinking on this sorts of stuff. Yeah, thank you so much for your time. It's really been a wonderful conversation.
Kaj: Thank you. Glad to be talking about this.
Lucas: If you enjoyed this podcast, please subscribe, give it a like, or share it on your preferred social media platform. We'll be back again soon with another episode in the AI Alignment series.



