Verifiable Training of AI Models
Contents
This collaboration between the Future of Life Institute and Mithril Security explores how to establish verifiable training processes for AI models using cryptographic guarantees. It presents a proof-of-concept for a Secure AI Bill of Materials, rooted in hardware-based security features, to ensure transparency, traceability, and compliance with emerging regulations. This project aims to enable stakeholders to verify the integrity and origin of AI models, ensuring their safety and authenticity to mitigate the risks associated with unverified or tampered models.
See our other post with Mithril Security on secure hardware solutions for safe AI deployment.
Executive Summary
The increasing reliance on AI for critical decisions underscores the need for trust and transparency in AI models. Regulatory bodies like the UK AI Safety Institute and the US AI Safety Institute, as well as companies themselves and independent evaluation firms, have established safety test procedures. But the black-box nature of AI system model weights renders such audits very different from standard software; crucial vulnerabilities, such as security loopholes or backdoors, can be hidden in the model weights. Additionally, this opacity makes it possible for the model provider to “game” the evaluations (design a model to perform well on specific tests while exhibiting different behaviors under actual use conditions) without being detected. Finally, an auditor cannot even be sure that a set of weights resulted from a given set of inputs, as weights are generally non-reproducible.
Likewise “open-sourcing” AI models promote transparency but even when this includes source code, training data, and training methods (which it often does not), the method falls short without a reliable provenance system to tie a particular set of weights to those elements of production. This means users of open-source models cannot be assured of the model’s true characteristics and vulnerabilities, potentially leading to misuse or unrecognized risks. Meanwhile, legislative efforts such as the EU AI Act and the U.S. Algorithmic Accountability Act require detailed documentation, yet they rely on trusting the provider’s claims as there is no technical proof to back those claims.
AI “Bills of Materials (BOMs)” have been proposed in analog to software BOMs to address these issues by providing a detailed document of an AI model’s origin and characteristics, linking technical evidence with training data, procedures, costs, and compliance information. However the black-box and irreproducible nature of model weights leaves a huge security hole in this concept in comparison to a software BOM. Because of model training’s non-deterministic nature and the resources required to retrain a model, an AIBOM cannot be validated by testing the retraining of the model from the same origin and characteristics. What is needed is for each training process step to be recorded and certified by a trusted system or third party, ensuring the model’s transparency and integrity.
Fortunately, security features of modern hardware allow this to be done without relying on a trusted third party but rather on cryptographic methods. The proof-of-concept described in this article demonstrates the use of Trusted Platform Modules (TPMs) to bind inputs and outputs of the fine-tuning process (a stand-in for a full training process), offering cryptographic proof of model provenance. This demonstrates the viability and potential of a full-feature Secure AI BOM that can ensure that the full software stack used during training is verifiable.
1- Transparency in AI is crucial
The growing use of AI for critical decision-making in all sectors raises concerns about choosing which models to trust. As frontier models develop rapidly, their capabilities in high-risk domains such as cybersecurity could reach very high levels in the near future. This urgency necessitates immediate solutions to ensure AI transparency, safety and verifiability, given the potential national security and public safety implications. From a human point of view, AI models are black boxes whose reasoning cannot be inspected: their billions of parameters cannot be verified as software code can be, and malicious behaviors can easily be hidden by the model developer, or even the model itself. A critical example was described in Anthropic’s paper ‘Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training Paper’. They managed to train a “sleeper agent” model to mimic compliant behavior during evaluation and later shift to undesirable behaviors, as a sleeper agent would.
The UK AI Safety Institute and the US AI Safety Institute are developing test procedures to assess models’ safety levels. However, there are persistent concerns that model suppliers may overtrain their models on the test sets or use the techniques described in the Anthropic paper to cheat and improve their scores. Malicious AI providers could use these strategies to pass safety tests and get their models approved. Knowing exhaustively which data a model has been trained on and fine-tuned is essential to address this risk of models being manipulated to avoid failing safety tests.
Model transparency, including clear documentation on model training, is also an essential requirement in the recent EU AI Act and the U.S. Algorithmic Accountability Act. As an example, the model provider must clearly state the amount of computing power used during the training (and consequently the environmental impact of the model development). Yet all those efforts on AI transparency still rely on a fundamental prerequisite: one must trust in the model provider’s claims on how a model was trained. There is no technical solution for a model developer to prove to another party how they trained a model. A model provider could present a false or partial training set or training procedure, and there would be no way to know whether it is legitimate. Even if not malicious, given competitive pressures and the often experimental nature of new AI systems, there will be numerous incentives for model developers to under-report how much training actually goes into a model or how many unplanned variations and changes were inserted to get a working product, if there aren’t clear standards and a verifiable audit trail.
This absence of technical proof around AI model provenance also exposes users to risks linked to the model “identity”. For instance, audited properties may actually not be the ones of the model in production. An external auditor may rightfully certify a model has a given property, like does not have IP-protected data in its weights, but a malicious provider could then put another model into production. The users will have no way to tell. This lack of technically verifiable training procedures is also a big limitation to enforcing recent AI regulations: with no technical evidence to ensure honest compliance with transparency requisites, many requirements will remain more declarative than really enforceable.
A system to enforce AI reliability should combine the following two key capabilities to address the AI traceability risks described above:
- Auditors must have a provable means to discover comprehensive details about a model’s development, including the data used for training, the computational resources expended, and the procedures followed.
- Users must have a verifiable method to identify the specific model they are interacting with, alongside access to the results of various evaluations to accurately gauge the model’s capabilities and vulnerabilities.
2- Documentation with no technical proof is not enough
Full open-sourcing of an AI model (beyond releasing just weights) can foster transparency by allowing anyone to gain insight into model weights, training sets, and algorithms. Collaboration and cross-checking in the open-source community can help identify and fix issues like bias, ensuring the development of responsible AI systems.
However, it is generally not feasible to reproduce a given set of model weights from the inspectable ingredients: even with identical code and data, running the training process multiple times can yield different results. (And even if feasible, it would not be desirable given the high cost and environmental expense of training large models.) So open-sourcing a model and accompanying training code and data is not proof that it was indeed trained in the way publicly described or that it has the described characteristics.
In short, even the most transparent model necessitates third parties trusting the AI provider with its training procedure disclosure. This is insufficient: transparency efforts are only truly reliable if model provenance and production steps can be demonstrated, i.e., if one can technically prove a given model was created with given inputs.
3- The AI Bill of Material (AIBOM) approach
AIBOM, inspired by traditional manufacturing’s Bill of Material, aims to solve the transparency challenge in AI by providing a reference document detailing the origin and characteristics of AI models and including verifiable proofs. This document is cryptographically bound to the model weights, ensuring they are inextricably linked through secure cryptographic methods. Any change in the model weights would be detectable, thus preserving the document’s integrity and authenticity. By linking technical evidence with all required information about the model—such as training data, procedures, costs, and legislative compliance information—AIBOM offers assurances about the model’s reliability.
A reliable AIBOM represents a significant shift towards ensuring AI models have genuinely transparent attributes. The AI training process consists of repetitive adaptation of the model to the entire training dataset, allowing the model to learn from the data iteratively and adjust its weights accordingly. To achieve AI traceability, for each adaptation of the model, all model training inputs (code, procedure, and input data) and outputs (weights produced) must be recorded in a document certified by a trusted system or third party.
This approach benefits users by enabling visibility into the model’s origin, and auditors can verify the integrity of the model. Proof systems also simplify compliance verification for regulators. In November 2023, the United States Army issued a Request for Information (RFI) for Project Linchpin AI Bill of Materials, acknowledging the criticality of such measures and contemplating the implementation of an AI Bill of Materials to safeguard the integrity and security of AI applications.
Several initiatives are under research to propose verifiable traceability solutions for AI. “Model Transparency” is one such initiative that aims to secure the AI supply chain. The current version of Model Transparency does not support GPUs, which is a big show-stopper for adopting a secure BOM solution for AI training and fine-tuning. To cope with this limitation and foster AIBOM adoption, we created AICert, designed to enable the utilization of GPU capabilities.
4- Proof-of-concept – A hardware-based AIBOM project
The Future of Life Institute, a leading NGO advocating for AI system safety, has teamed up with Mithril Security, a startup pioneering secure hardware with enclave-based solutions for trustworthy AI. This collaboration aims to showcase how an AI Bill of Material can be established to ensure traceability and transparency using cryptographic guarantees.
In this project, we present a proof-of-concept for verifiable AI model training. The core scenario to address involves two key parties:
- The AI model builder, who seeks to train an AI model with verifiable properties;
- The AI verifier, who aims to verify that a given model adheres to certain properties (e.g., compute used, non-copyrighted data used, absence of backdoor, etc.)
To do so, this project proposes a solution to train models and generate unforgeable AIBOM that cryptographically attests to the model’s properties.
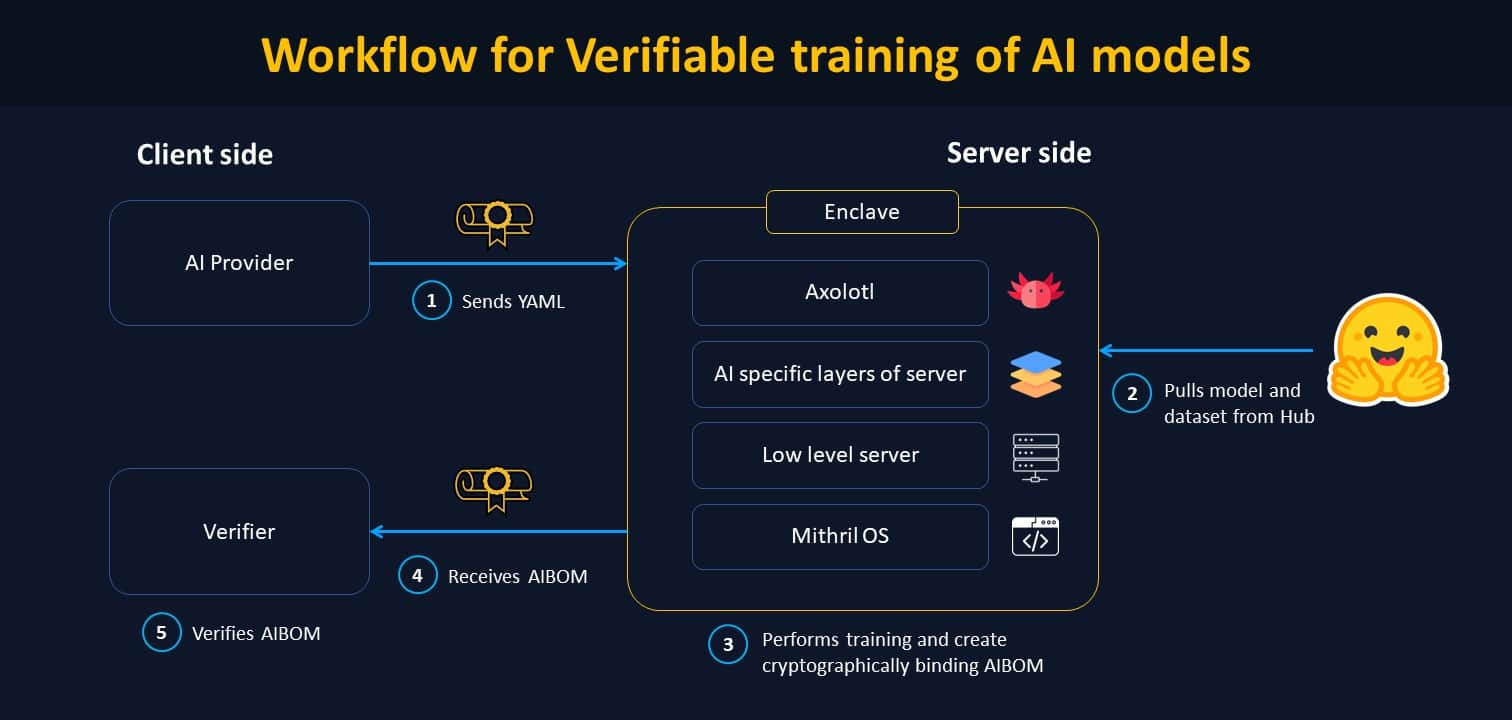
Through this collaboration, we have developed a framework that transforms model training inputs (i.e., the code containing the procedure like an Axolotl configuration) into a Secure AIBOM that binds the output weights with specific properties (code used, amount of compute, training procedure, and training data). This link is cryptographically binding and non-forgeable, allowing AI training to move from declarative to provable. If one has access to the data itself, one can verify if the cryptographic hash of the training data indeed corresponds to the claimed training data.
This approach allows the AI verifier to confirm that the data used for fine-tuning matches the claimed training data. Stakeholders can ensure that the fine-tuning was conducted with the specified data without any unauthorized changes or additional data. The verifier can attest the fine-tuning respected the expected compute usage, did not incorporate copyrighted data, and did not introduce any backdoors.
How does it work?
The solution is based on Trusted Platform Modules (TPMs). TPMs are specialized hardware components designed to enhance computer security. They are currently used to perform crucial cryptographic functions, including generating and securely storing encryption keys, passwords, and digital certificates. TPMs can verify system integrity, assist in device authentication, and support secure boot processes. TPMs are available in the motherboards of most servers today and can be used to secure computer stacks, including GPUs.
These cryptographic modules serve as the foundation of AICert (the system developed during this project), ensuring the integrity of the entire software supply chain. By measuring the whole hardware and software stack and binding the final weights in the registers, TPMs create certificates offering irrefutable proof of model provenance.
The system is first measured to ensure that the system components have not been tampered with or altered. When the system boots, various measurements are taken, including hashes of firmware, the bootloader, and critical system files. If someone attempts to modify the machine’s state, the measured values will be altered. Then, TPMs bind the inputs (the model procedure and the input data) and outputs (the model weights) of the training process, providing cryptographic proof of model provenance. This way, the end users can verify the entire software stack used during the training, ensuring transparency and trustworthiness in AI model deployment.
Our work could provide the foundation for a framework where regulators could verify the compliance of AI models used within their jurisdictions, ensuring these models adhere to local regulations and do not expose users to security risks.
5- Open-source deliverables available
This proof of concept is made open-source under an Apache-2.0 license.
We provide the following resources to explore in more detail our collaboration on AI traceability and transparency:
- A demo to understand how controlled hardware-based AI transparency works and looks like in practice.
- Code is made open-source to reproduce our results.
- Technical documentation to dig into the specifics of the implementation.
6- Future investigations
This POC serves as a demonstrator of how cryptographic proofs from vTPM can create unforgeable AIBOM. However, limitations exist. Currently, only publicly available online data, an Azure account, and GPU resources on Azure are required for training. AICert lacks auditing by a third party, and its robustness has yet to be tested. Additionally, the project has yet to address the detection of poisoned models and datasets used. This PoC is only made verifiable for fine-tuning. Further development is required to use it for training AI models from scratch. Feedback is welcome and crucial to refining its efficacy.
After the first project on controlled AI model consumption (AIgovToo), this second project marks the next phase in the ongoing collaboration between Mithril Security and FLI to help establish a hardware-based AI compute security and governance framework. This broader initiative aims to enforce AI security and governance throughout its lifecycle by implementing verifiable security measures.
Upcoming projects will expand hardware and cloud provider systems support within our open-source governance framework. The first step will be to integrate with Azure’s Confidential Computing GPU.
See our other post with Mithril Security on secure hardware solutions for safe AI deployment.
About Mithril Security
Mithril Security is a deep-tech cybersecurity startup specializing in deploying confidential AI workloads in trusted environments. We create an open-source framework that empowers AI providers to build secure AI environments, known as enclaves, to protect data privacy and ensure the confidentiality of model weights.
Interested in AI safety challenges? Visit our blog to learn more.
About the Future of Life Institute
The Future of Life Institute (FLI) is the world’s oldest and largest AI think tank, with a team of 35+ full-time staff operating across the US and Europe. FLI has been working to steer the development of transformative technologies towards benefitting life and away from extreme large-scale risks since its founding in 2014. Find out more about our mission or explore our work.
Related content
Other posts about AI, Technical safety

Governor DeSantis Directs Florida State Agencies to Partner with Future of Life Institute to Shield Families from AI Harm

Statement from Max Tegmark on the Department of War’s ultimatum

The U.S. Public Wants Regulation (or Prohibition) of Expert‑Level and Superhuman AI
