Machine Learning Security at ICLR 2017
Contents

The overall theme of the ICLR conference setting this year could be summarized as “finger food and ships”. More importantly, there were a lot of interesting papers, especially on machine learning security, which will be the focus on this post. (Here is a great overview of the topic.)
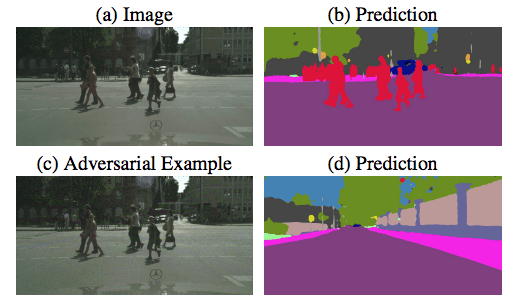
On the attack side, adversarial perturbations now work in physical form (if you print out the image and then take a picture) and they can also interfere with image segmentation. This has some disturbing implications for fooling vision systems in self-driving cars, such as impeding them from recognizing pedestrians. Adversarial examples are also effective at sabotaging neural network policies in reinforcement learning at test time.



In more encouraging news, adversarial examples are not entirely transferable between different models. For targeted examples, which aim to be misclassified as a specific class, the target class is not preserved when transferring to a different model. For example, if an image of a school bus is classified as a crocodile by the original model, it has at most 4% probability of being seen as a crocodile by another model. The paper introduces an ensemble method for developing adversarial examples whose targets do transfer, but this seems to only work well if the ensemble includes a model with a similar architecture to the new model.
On the defense side, there were some new methods for detecting adversarial examples. One method augments neural nets with a detector subnetwork, which works quite well and generalizes to new adversaries (if they are similar to or weaker than the adversary used for training). Another approach analyzes adversarial images using PCA, and finds that they are similar to normal images in the first few thousand principal components, but have a lot more variance in later components. Note that the reverse is not the case – adding arbitrary variation in trailing components does not necessarily encourage misclassification.

There has also been progress in scaling adversarial training to larger models and data sets, which also found that higher-capacity models are more resistant against adversarial examples than lower-capacity models. My overall impression is that adversarial attacks are still ahead of adversarial defense, but the defense side is starting to catch up.

(This article originally appeared here. Thanks to Janos Kramar for his feedback on this post.)
About the Future of Life Institute
The Future of Life Institute (FLI) is a global think tank with a team of 20+ full-time staff operating across the US and Europe. FLI has been working to steer the development of transformative technologies towards benefitting life and away from extreme large-scale risks since its founding in 2014. Find out more about our mission or explore our work.
Related content
Other posts about AI



