The Top A.I. Breakthroughs of 2015

Contents
Progress in artificial intelligence and machine learning has been impressive this year. Those in the field acknowledge progress is accelerating year by year, though it is still a manageable pace for us. The vast majority of work in the field these days actually builds on previous work done by other teams earlier the same year, in contrast to most other fields where references span decades.
Creating a summary of a wide range of developments in this field will almost invariably lead to descriptions that sound heavily anthropomorphic, and this summary does indeed. Such metaphors, however, are only convenient shorthands for talking about these functionalities. It’s important to remember that even though many of these capabilities sound very thought-like, they’re usually not very similar to how human cognition works. The systems are all of course functional and mechanistic, and, though increasingly less so, each are still quite narrow in what they do. Be warned though: in reading this article, these functionalities may seem to go from fanciful to prosaic.
The biggest developments of 2015 fall into five categories of intelligence: abstracting across environments, intuitive concept understanding, creative abstract thought, dreaming up visions, and dexterous fine motor skills. I’ll highlight a small number of important threads within each that have brought the field forward this year.
Abstracting Across Environments
A long-term goal of the field of AI is to achieve artificial general intelligence, a single learning program that can learn and act in completely different domains at the same time, able to transfer some skills and knowledge learned in, e.g., making cookies and apply them to making brownies even better than it would have otherwise. A significant stride forward in this realm of generality was provided by Parisotto, Ba, and Salakhutdinov. They built on DeepMind’s seminal DQN, published earlier this year in Nature, that learns to play many different Atari games well.
Instead of using a fresh network for each game, this team combined deep multitask reinforcement learning with deep-transfer learning to be able to use the same deep neural network across different types of games. This leads not only to a single instance that can succeed in multiple different games, but to one that also learns new games better and faster because of what it remembers about those other games. For example, it can learn a new tennis video game faster because it already gets the concept — the meaningful abstraction of hitting a ball with a paddle — from when it was playing Pong. This is not yet general intelligence, but it erodes one of the hurdles to get there.
Reasoning across different modalities has been another bright spot this year. The Allen Institute for AI and University of Washington have been working on test-taking AIs, over the years working up from 4th grade level tests to 8th grade level tests, and this year announced a system that addresses the geometry portion of the SAT. Such geometry tests contain combinations of diagrams, supplemental information, and word problems. In more narrow AI, these different modalities would typically be analyzed separately, essentially as different environments. This system combines computer vision and natural language processing, grounding both in the same structured formalism, and then applies a geometric reasoner to answer the multiple-choice questions, matching the performance of the average American 11th grade student.
Intuitive Concept Understanding
A more general method of multimodal concept grounding has come about from deep learning in the past few years: Subsymbolic knowledge and reasoning are implicitly understood by a system rather than being explicitly programmed in or even explicitly represented. Decent progress has been made this year in the subsymbolic understanding of concepts that we as humans can relate to. This progress helps with the age-old symbol grounding problem — how symbols or words get their meaning. The increasingly popular way to achieve this grounding these days is by joint embeddings — deep distributed representations where different modalities or perspectives on the same concept are placed very close together in a high-dimensional vector space.
Last year, this technique helped power abilities like automated image caption writing, and this year a team from Stanford and Tel Aviv University have extended this basic idea to jointly embed images and 3D shapes to bridge computer vision and graphics. Rajendran et al. then extended joint embeddings to support the confluence of multiple meaningfully related mappings at once, across different modalities and different languages. As these embeddings get more sophisticated and detailed, they can become workhorses for more elaborate AI techniques. Ramanathan et al. have leveraged them to create a system that learns a meaningful schema of relationships between different types of actions from a set of photographs and a dictionary.
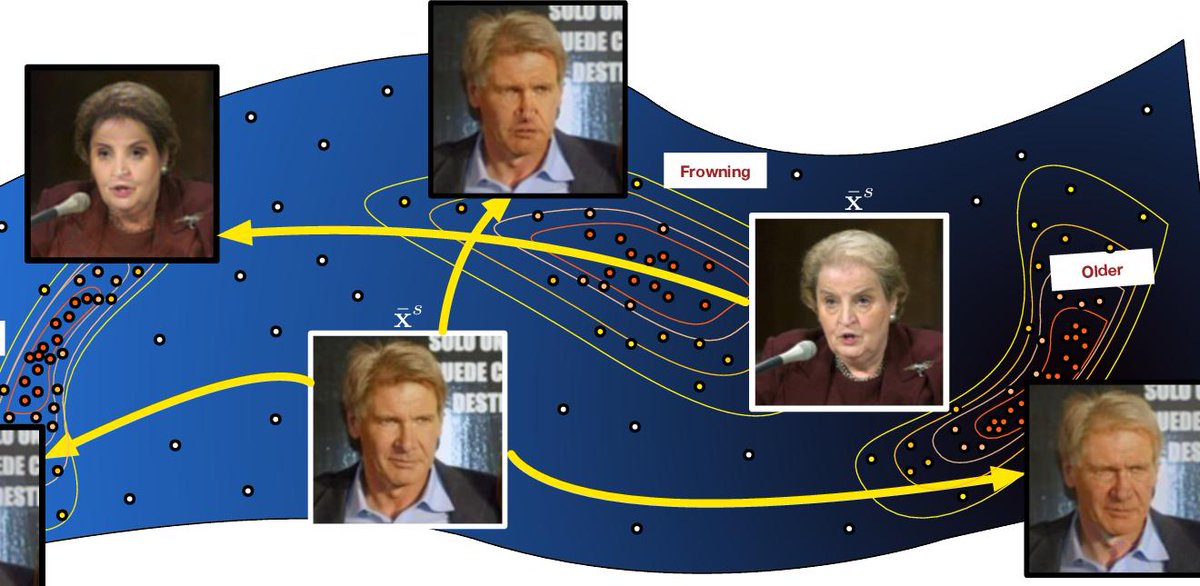
As single systems increasingly do multiple things, and as deep learning is predicated on, any lines between the features of the data and the learned concepts will blur away. Another demonstration of this deep feature grounding, by a team from Cornell and WUStL, uses a dimensionality reduction of a deep net’s weights to form a surface of convolutional features that can simply be slid along to meaningfully, automatically, photorealistically alter particular aspects of photographs, e.g., changing people’s facial expressions or their ages, or colorizing photos.
One hurdle in deep learning techniques is that they require a lot of training data to produce good results. Humans, on the other hand, are often able to learn from just a single example. Salakhutdinov, Tenenbaum, and Lake have overcome this disparity with a technique for human-level concept learning through Bayesian program induction from a single example. This system is then able to, for instance, draw variations on symbols in a way indistinguishable from those drawn by humans.
Creative Abstract Thought
Beyond understanding simple concepts lies grasping aspects of causal structure — understanding how ideas tie together to make things happen or tell a story in time — and to be able to create things based on those understandings. Building on the basic ideas from both DeepMind’s neural Turing machine and Facebook’s memory networks, combinations of deep learning and novel memory architectures have shown great promise in this direction this year. These architectures provide each node in a deep neural network with a simple interface to memory.
Kumar and Socher’s dynamic memory networks improved on memory networks with better support for attention and sequence understanding. Like the original, this system could read stories and answer questions about them, implicitly learning 20 kinds of reasoning, like deduction, induction, temporal reasoning, and path finding. It was never programmed with any of those kinds of reasoning. Weston et al’s more recent end-to-end memory networks then added the ability to perform multiple computational hops per output symbol, expanding modeling capacity and expressivity to be able to capture things like out-of-order access, long term dependencies, and unordered sets, further improving accuracy on such tasks.
Programs themselves are of course also data, and they certainly make use of complex causal, structural, grammatical, sequence-like properties, so programming is ripe for this approach. Last year, neural Turing machines proved deep learning of programs to be possible. This year, Grefenstette et al. showed how programs can be transduced, or generatively figured out from sample output, much more efficiently than with neural Turing machines, by using a new type of memory-based recurrent neural networks (RNNs) where the nodes simply access differentiable versions of data structures such as stacks and queues. Reed and de Freitas of DeepMind have also recently shown how their neural programmer-interpreter can represent lower-level programs that control higher-level and domain-specific functionalities.
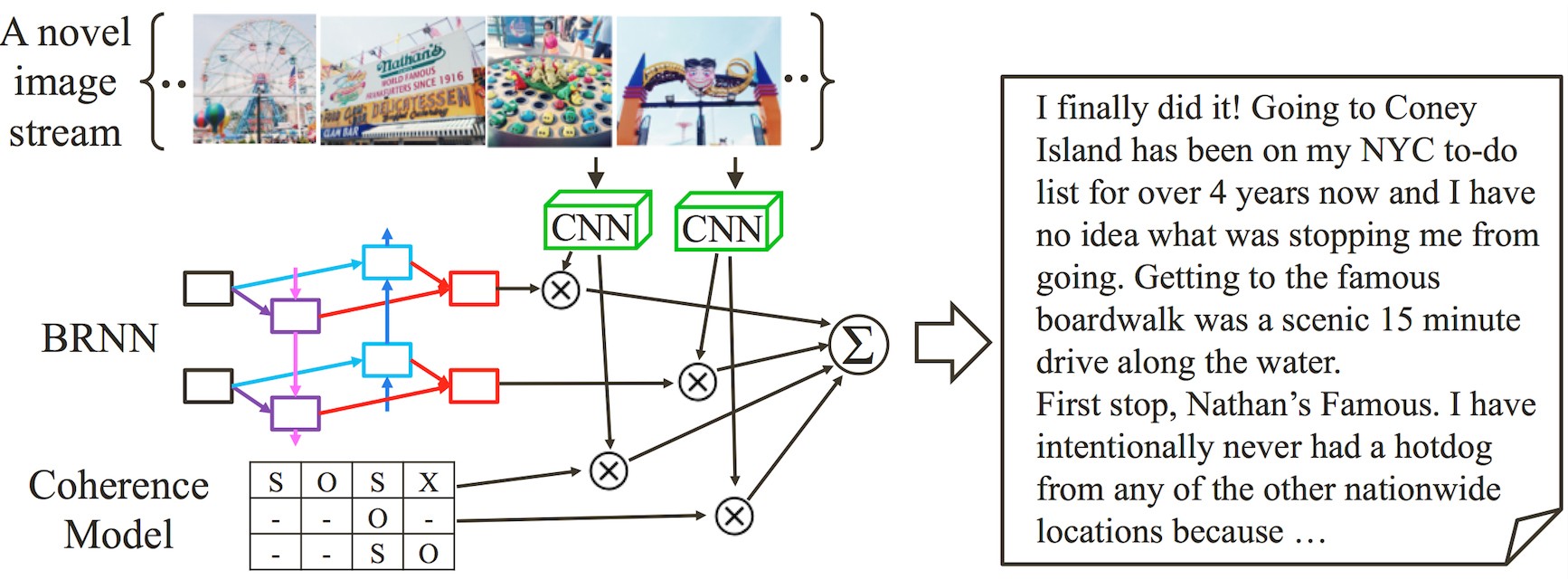
Another example of proficiency in understanding time in context, and applying that to create new artifacts, is a rudimentary but creative video summarization capability developed this year. Park and Kim from Seoul National U. developed a novel architecture called a coherent recurrent convolutional network, applying it to creating novel and fluid textual stories from sequences of images.
Another important modality that includes causal understanding, hypotheticals, and creativity in abstract thought is scientific hypothesizing. A team at Tufts combined genetic algorithms and genetic pathway simulation to create a system that arrived at the first significant new AI-discovered scientific theory of how exactly flatworms are able to regenerate body parts so readily. In a couple of days it had discovered what eluded scientists for a century. This should provide a resounding answer to those who question why we would ever want to make AIs curious in the first place.
Dreaming Up Visions
AI did not stop at writing programs, travelogues, and scientific theories this year. There are AIs now able to imagine, or using the technical term, hallucinate, meaningful new imagery as well. Deep learning isn’t only good at pattern recognition, but indeed pattern understanding and therefore also pattern creation.
A team from MIT and Microsoft Research have created a deep convolution inverse graphic network, which, among other things, contains a special training technique to get neurons in its graphics code layer to differentiate to meaningful transformations of an image. In so doing, they are deep-learning a graphics engine, able to understand the 3D shapes in novel 2D images it receives, and able to photorealistically imagine what it would be like to change things like camera angle and lighting.
A team from NYU and Facebook devised a way to generate realistic new images from meaningful and plausible combinations of elements it has seen in other images. Using a pyramid of adversarial networks — with some trying to produce realistic images and others critically judging how real the images look — their system is able to get better and better at imagining new photographs. Though the examples online are quite low-res, offline I’ve seen some impressive related high-res results.
Also significant in ’15 is the ability to deeply imagine entirely new imagery based on short English descriptions of the desired picture. While scene renderers taking symbolic, restricted vocabularies have been around a while, this year has seen the advent of a purely neural system doing this in a way that’s not explicitly programmed. This University of Toronto team applies attention mechanisms to generation of images incrementally based on the meaning of each component of the description, in any of a number of ways per request. So androids can now dream of electric sheep.
There has even been impressive progress in computational imagination of new animated video clips this year. A team from the University of Michigan created a deep analogy system that recognizes complex implicit relationships in exemplars and is able to apply that relationship as a generative transformation of query examples. They’ve applied this in a number of synthetic applications, but most impressive is the demo (from the 10:10-11:00 mark of the video embedded below), where an entirely new short video clip of an animated character is generated based on a single still image of the never-before-seen target character, along with a comparable video clip of a different character at a different angle.
While the generation of imagery was used in these for ease of demonstration, their techniques for computational imagination are applicable across a wide variety of domains and modalities. Picture these applied to voices, or music, for instance.
Agile and Dexterous Fine Motor Skills
This year’s progress in AI hasn’t been confined to computer screens.
Earlier in the year, a German primatology team has recorded the hand motions of primates in tandem with corresponding neural activity, and they’re able to predict, based on brain activity, what fine motions are going on. They’ve also been able to teach those same fine motor skills to robotic hands, aiming at neural-enhanced prostheses.
In the middle of the year, a team at U.C. Berkeley announced a much more general and easier way to teach robots fine motor skills. They applied deep reinforcement learning-based guided policy search to get robots to be able to screw caps on bottles, to use the back of a hammer to remove a nail from wood, and other seemingly every day actions. These are the kind of actions that are typically trivial for people but very difficult for machines, and this team’s system matches human dexterity and speed at these tasks. It actually learns to do these actions by trying to do them using hand-eye coordination, and by practicing, refining its technique after just a few tries.
Watch This Space
This is by no means a comprehensive list of the impressive feats in AI and machine learning (ML) for the year. There are also many more foundational discoveries and developments that have occurred this year, including some that I fully expect to be more revolutionary than any of the above. But those are in early days and so out of the scope of these top picks.
This year has certainly provided some impressive progress. But we expect to see even more in 2016. Coming up next year, I expect to see some more radical deep architectures, better integration of the symbolic and subsymbolic, some impressive dialogue systems, an AI finally dominating the game of Go, deep learning being used for more elaborate robotic planning and motor control, high-quality video summarization, and more creative and higher-resolution dreaming, which should all be quite a sight. What’s even more exciting are the developments we don’t expect.
About the Future of Life Institute
The Future of Life Institute (FLI) is the world’s oldest and largest AI think tank, with a team of 35+ full-time staff operating across the US and Europe. FLI has been working to steer the development of transformative technologies towards benefitting life and away from extreme large-scale risks since its founding in 2014. Find out more about our mission or explore our work.
Related content
Other posts about AI, Recent News

Governor DeSantis Directs Florida State Agencies to Partner with Future of Life Institute to Shield Families from AI Harm

Statement from Max Tegmark on the Department of War’s ultimatum

The U.S. Public Wants Regulation (or Prohibition) of Expert‑Level and Superhuman AI
