Benefits & Risks of Artificial Intelligence

Contents
Click here to see this page in other languages: Chinese ![]() French
French ![]() German
German![]() Japanese
Japanese ![]() Korean
Korean ![]() Russian
Russian ![]()
“Everything we love about civilization is a product of intelligence, so amplifying our human intelligence with artificial intelligence has the potential of helping civilization flourish like never before – as long as we manage to keep the technology beneficial.“
Max Tegmark, President of the Future of Life Institute
What is AI?
From SIRI to self-driving cars, artificial intelligence (AI) is progressing rapidly. While science fiction often portrays AI as robots with human-like characteristics, AI can encompass anything from Google’s search algorithms to IBM’s Watson to autonomous weapons.
Artificial intelligence today is properly known as narrow AI (or weak AI), in that it is designed to perform a narrow task (e.g. only facial recognition or only internet searches or only driving a car). However, the long-term goal of many researchers is to create general AI (AGI or strong AI). While narrow AI may outperform humans at whatever its specific task is, like playing chess or solving equations, AGI would outperform humans at nearly every cognitive task.
Why research AI safety?
In the near term, the goal of keeping AI’s impact on society beneficial motivates research in many areas, from economics and law to technical topics such as verification, validity, security and control. Whereas it may be little more than a minor nuisance if your laptop crashes or gets hacked, it becomes all the more important that an AI system does what you want it to do if it controls your car, your airplane, your pacemaker, your automated trading system or your power grid. Another short-term challenge is preventing a devastating arms race in lethal autonomous weapons.
In the long term, an important question is what will happen if the quest for strong AI succeeds and an AI system becomes better than humans at all cognitive tasks. As pointed out by I.J. Good in 1965, designing smarter AI systems is itself a cognitive task. Such a system could potentially undergo recursive self-improvement, triggering an intelligence explosion leaving human intellect far behind. By inventing revolutionary new technologies, such a superintelligence might help us eradicate war, disease, and poverty, and so the creation of strong AI might be the biggest event in human history. Some experts have expressed concern, though, that it might also be the last, unless we learn to align the goals of the AI with ours before it becomes superintelligent.
There are some who question whether strong AI will ever be achieved, and others who insist that the creation of superintelligent AI is guaranteed to be beneficial. At FLI we recognize both of these possibilities, but also recognize the potential for an artificial intelligence system to intentionally or unintentionally cause great harm. We believe research today will help us better prepare for and prevent such potentially negative consequences in the future, thus enjoying the benefits of AI while avoiding pitfalls.
AI Existential Safety Community
We believe research today will help us better prepare for and prevent such potentially negative consequences in the future, thus enjoying the benefits of AI while avoiding pitfalls. Click here to view our growing community of AI existential safety researchers.
How can AI be dangerous?
Most researchers agree that a superintelligent AI is unlikely to exhibit human emotions like love or hate, and that there is no reason to expect AI to become intentionally benevolent or malevolent. Instead, when considering how AI might become a risk, experts think two scenarios most likely:
- The AI is programmed to do something devastating: Autonomous weapons are artificial intelligence systems that are programmed to kill. In the hands of the wrong person, these weapons could easily cause mass casualties. Moreover, an AI arms race could inadvertently lead to an AI war that also results in mass casualties. To avoid being thwarted by the enemy, these weapons would be designed to be extremely difficult to simply “turn off,” so humans could plausibly lose control of such a situation. This risk is one that’s present even with narrow AI, but grows as levels of AI intelligence and autonomy increase.
- The AI is programmed to do something beneficial, but it develops a destructive method for achieving its goal: This can happen whenever we fail to fully align the AI’s goals with ours, which is strikingly difficult. If you ask an obedient intelligent car to take you to the airport as fast as possible, it might get you there chased by helicopters and covered in vomit, doing not what you wanted but literally what you asked for. If a superintelligent system is tasked with a ambitious geoengineering project, it might wreak havoc with our ecosystem as a side effect, and view human attempts to stop it as a threat to be met.
Example: Lethal autonomous weapons
Slaughterbots, also called “lethal autonomous weapons systems” or “killer robots”, are weapons systems that use artificial intelligence (AI) to identify, select, and kill human targets without human intervention.
This technology is already here – and it poses some huge risks. Learn more about lethal autonomous weapons, and what we can do to prevent them, here.
As these examples illustrate, the concern about advanced AI isn’t malevolence but competence. A super-intelligent AI will be extremely good at accomplishing its goals, and if those goals aren’t aligned with ours, we have a problem. You’re probably not an evil ant-hater who steps on ants out of malice, but if you’re in charge of a hydroelectric green energy project and there’s an anthill in the region to be flooded, too bad for the ants. A key goal of AI safety research is to never place humanity in the position of those ants.
Why the recent interest in AI safety
Stephen Hawking, Elon Musk, Steve Wozniak, Bill Gates, and many other big names in science and technology have recently expressed concern in the media and via open letters about the risks posed by AI, joined by many leading AI researchers. Why is the subject suddenly in the headlines?
The idea that the quest for strong AI would ultimately succeed was long thought of as science fiction, centuries or more away. However, thanks to recent breakthroughs, many AI milestones, which experts viewed as decades away merely five years ago, have now been reached, making many experts take seriously the possibility of superintelligence in our lifetime. While some experts still guess that human-level AI is centuries away, most AI researches at the 2015 Puerto Rico Conference guessed that it would happen before 2060. Since it may take decades to complete the required safety research, it is prudent to start it now.
Because AI has the potential to become more intelligent than any human, we have no surefire way of predicting how it will behave. We can’t use past technological developments as much of a basis because we’ve never created anything that has the ability to, wittingly or unwittingly, outsmart us. The best example of what we could face may be our own evolution. People now control the planet, not because we’re the strongest, fastest or biggest, but because we’re the smartest. If we’re no longer the smartest, are we assured to remain in control?
FLI’s position is that our civilization will flourish as long as we win the race between the growing power of technology and the wisdom with which we manage it. In the case of AI technology, FLI’s position is that the best way to win that race is not to impede the former, but to accelerate the latter, by supporting AI safety research.
The Top Myths About Advanced AI
A captivating conversation is taking place about the future of artificial intelligence and what it will/should mean for humanity. There are fascinating controversies where the world’s leading experts disagree, such as: AI’s future impact on the job market; if/when human-level AI will be developed; whether this will lead to an intelligence explosion; and whether this is something we should welcome or fear. But there are also many examples of of boring pseudo-controversies caused by people misunderstanding and talking past each other. To help ourselves focus on the interesting controversies and open questions — and not on the misunderstandings — let’s clear up some of the most common myths.
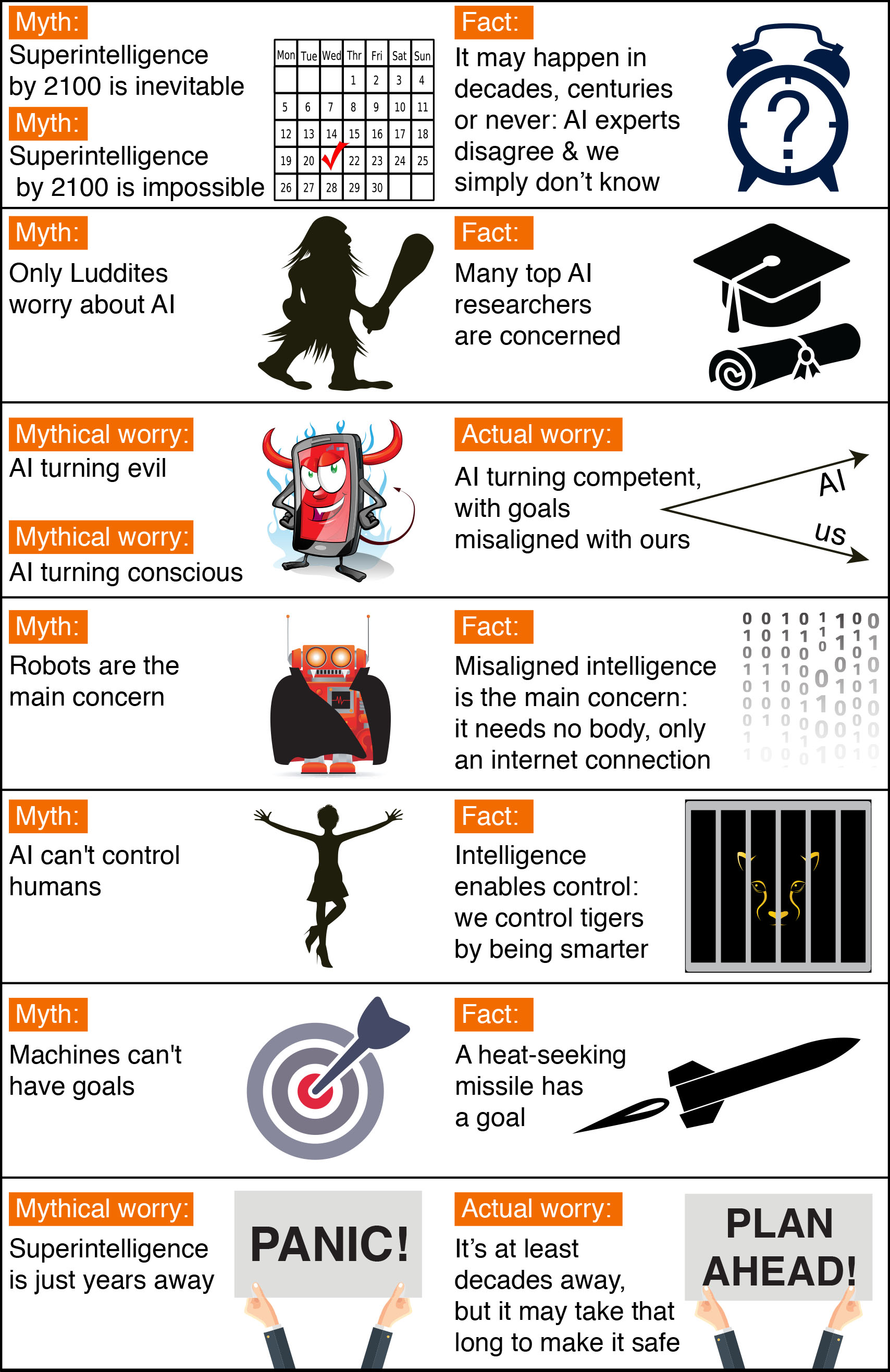
Timeline Myths
The first myth regards the timeline: how long will it take until machines greatly supersede human-level intelligence? A common misconception is that we know the answer with great certainty.
One popular myth is that we know we’ll get superhuman AI this century. In fact, history is full of technological over-hyping. Where are those fusion power plants and flying cars we were promised we’d have by now? AI has also been repeatedly over-hyped in the past, even by some of the founders of the field. For example, John McCarthy (who coined the term “artificial intelligence”), Marvin Minsky, Nathaniel Rochester and Claude Shannon wrote this overly optimistic forecast about what could be accomplished during two months with stone-age computers: “We propose that a 2 month, 10 man study of artificial intelligence be carried out during the summer of 1956 at Dartmouth College […] An attempt will be made to find how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves. We think that a significant advance can be made in one or more of these problems if a carefully selected group of scientists work on it together for a summer.”
On the other hand, a popular counter-myth is that we know we won’t get superhuman AI this century. Researchers have made a wide range of estimates for how far we are from superhuman AI, but we certainly can’t say with great confidence that the probability is zero this century, given the dismal track record of such techno-skeptic predictions. For example, Ernest Rutherford, arguably the greatest nuclear physicist of his time, said in 1933 — less than 24 hours before Szilard’s invention of the nuclear chain reaction — that nuclear energy was “moonshine.” And Astronomer Royal Richard Woolley called interplanetary travel “utter bilge” in 1956. The most extreme form of this myth is that superhuman AI will never arrive because it’s physically impossible. However, physicists know that a brain consists of quarks and electrons arranged to act as a powerful computer, and that there’s no law of physics preventing us from building even more intelligent quark blobs.
There have been a number of surveys asking AI researchers how many years from now they think we’ll have human-level AI with at least 50% probability. All these surveys have the same conclusion: the world’s leading experts disagree, so we simply don’t know. For example, in such a poll of the AI researchers at the 2015 Puerto Rico AI conference, the average (median) answer was by year 2045, but some researchers guessed hundreds of years or more.
There’s also a related myth that people who worry about AI think it’s only a few years away. In fact, most people on record worrying about superhuman AI guess it’s still at least decades away. But they argue that as long as we’re not 100% sure that it won’t happen this century, it’s smart to start safety research now to prepare for the eventuality. Many of the safety problems associated with human-level AI are so hard that they may take decades to solve. So it’s prudent to start researching them now rather than the night before some programmers drinking Red Bull decide to switch one on.
Controversy Myths
Another common misconception is that the only people harboring concerns about AI and advocating AI safety research are luddites who don’t know much about AI. When Stuart Russell, author of the standard AI textbook, mentioned this during his Puerto Rico talk, the audience laughed loudly. A related misconception is that supporting AI safety research is hugely controversial. In fact, to support a modest investment in AI safety research, people don’t need to be convinced that risks are high, merely non-negligible — just as a modest investment in home insurance is justified by a non-negligible probability of the home burning down.
It may be that media have made the AI safety debate seem more controversial than it really is. After all, fear sells, and articles using out-of-context quotes to proclaim imminent doom can generate more clicks than nuanced and balanced ones. As a result, two people who only know about each other’s positions from media quotes are likely to think they disagree more than they really do. For example, a techno-skeptic who only read about Bill Gates’s position in a British tabloid may mistakenly think Gates believes superintelligence to be imminent. Similarly, someone in the beneficial-AI movement who knows nothing about Andrew Ng’s position except his quote about overpopulation on Mars may mistakenly think he doesn’t care about AI safety, whereas in fact, he does. The crux is simply that because Ng’s timeline estimates are longer, he naturally tends to prioritize short-term AI challenges over long-term ones.
Myths About the Risks of Superhuman AI
Many AI researchers roll their eyes when seeing this headline: “Stephen Hawking warns that rise of robots may be disastrous for mankind.” And as many have lost count of how many similar articles they’ve seen. Typically, these articles are accompanied by an evil-looking robot carrying a weapon, and they suggest we should worry about robots rising up and killing us because they’ve become conscious and/or evil. On a lighter note, such articles are actually rather impressive, because they succinctly summarize the scenario that AI researchers don’t worry about. That scenario combines as many as three separate misconceptions: concern about consciousness, evil, and robots.
If you drive down the road, you have a subjective experience of colors, sounds, etc. But does a self-driving car have a subjective experience? Does it feel like anything at all to be a self-driving car? Although this mystery of consciousness is interesting in its own right, it’s irrelevant to AI risk. If you get struck by a driverless car, it makes no difference to you whether it subjectively feels conscious. In the same way, what will affect us humans is what superintelligent AI does, not how it subjectively feels.
The fear of machines turning evil is another red herring. The real worry isn’t malevolence, but competence. A superintelligent AI is by definition very good at attaining its goals, whatever they may be, so we need to ensure that its goals are aligned with ours. Humans don’t generally hate ants, but we’re more intelligent than they are – so if we want to build a hydroelectric dam and there’s an anthill there, too bad for the ants. The beneficial-AI movement wants to avoid placing humanity in the position of those ants.
The consciousness misconception is related to the myth that machines can’t have goals. Machines can obviously have goals in the narrow sense of exhibiting goal-oriented behavior: the behavior of a heat-seeking missile is most economically explained as a goal to hit a target. If you feel threatened by a machine whose goals are misaligned with yours, then it is precisely its goals in this narrow sense that troubles you, not whether the machine is conscious and experiences a sense of purpose. If that heat-seeking missile were chasing you, you probably wouldn’t exclaim: “I’m not worried, because machines can’t have goals!”
I sympathize with Rodney Brooks and other robotics pioneers who feel unfairly demonized by scaremongering tabloids, because some journalists seem obsessively fixated on robots and adorn many of their articles with evil-looking metal monsters with red shiny eyes. In fact, the main concern of the beneficial-AI movement isn’t with robots but with intelligence itself: specifically, intelligence whose goals are misaligned with ours. To cause us trouble, such misaligned superhuman intelligence needs no robotic body, merely an internet connection – this may enable outsmarting financial markets, out-inventing human researchers, out-manipulating human leaders, and developing weapons we cannot even understand. Even if building robots were physically impossible, a super-intelligent and super-wealthy AI could easily pay or manipulate many humans to unwittingly do its bidding.
The robot misconception is related to the myth that machines can’t control humans. Intelligence enables control: humans control tigers not because we are stronger, but because we are smarter. This means that if we cede our position as smartest on our planet, it’s possible that we might also cede control.
The Interesting Controversies
Not wasting time on the above-mentioned misconceptions lets us focus on true and interesting controversies where even the experts disagree. What sort of future do you want? Should we develop lethal autonomous weapons? What would you like to happen with job automation? What career advice would you give today’s kids? Do you prefer new jobs replacing the old ones, or a jobless society where everyone enjoys a life of leisure and machine-produced wealth? Further down the road, would you like us to create superintelligent life and spread it through our cosmos? Will we control intelligent machines or will they control us? Will intelligent machines replace us, coexist with us, or merge with us? What will it mean to be human in the age of artificial intelligence? What would you like it to mean, and how can we make the future be that way? Please join the conversation!
Recommended References
Videos
- MinutePhysics: Myths and Facts About Superintelligent AI
- Max Tegmark: How to get empowered, not overpowered, by AI
- Stuart Russell: 3 principles for creating safer AI
- Sam Harris: Can we build AI without losing control over it?
- Talks from the Beneficial AI 2017 conference in Asilomar, CA
- Stuart Russell – The Long-Term Future of (Artificial) Intelligence
- Humans Need Not Apply
- Nick Bostrom: What happens when computers get smarter than we are?
- Value Alignment – Stuart Russell: Berkeley IdeasLab Debate Presentation at the World Economic Forum
- Social Technology and AI: World Economic Forum Annual Meeting 2015
- Stuart Russell, Eric Horvitz, Max Tegmark – The Future of Artificial Intelligence
- Jaan Tallinn on Steering Artificial Intelligence
Media Articles
- Concerns of an Artificial Intelligence Pioneer
- Transcending Complacency on Superintelligent Machines
- Why We Should Think About the Threat of Artificial Intelligence
- Stephen Hawking Is Worried About Artificial Intelligence Wiping Out Humanity
- Artificial Intelligence could kill us all. Meet the man who takes that risk seriously
- Artificial Intelligence Poses ‘Extinction Risk’ To Humanity Says Oxford University’s Stuart Armstrong
- What Happens When Artificial Intelligence Turns On Us?
- Can we build an artificial superintelligence that won’t kill us?
- Artificial intelligence: Our final invention?
- Artificial intelligence: Can we keep it in the box?
- Science Friday: Christof Koch and Stuart Russell on Machine Intelligence (transcript)
- Transcendence: An AI Researcher Enjoys Watching His Own Execution
- Science Goes to the Movies: ‘Transcendence’
- Our Fear of Artificial Intelligence
Essays by AI Researchers
- Stuart Russell: What do you Think About Machines that Think?
- Stuart Russell: Of Myths and Moonshine
- Jacob Steinhardt: Long-Term and Short-Term Challenges to Ensuring the Safety of AI Systems
- Eliezer Yudkowsky: Why value-aligned AI is a hard engineering problem
- Eliezer Yudkowsky: There’s No Fire Alarm for Artificial General Intelligence
- Open Letter: Research Priorities for Robust and Beneficial Artificial Intelligence
Research Articles
- Intelligence Explosion: Evidence and Import (MIRI)
- Intelligence Explosion and Machine Ethics (Luke Muehlhauser, MIRI)
- Artificial Intelligence as a Positive and Negative Factor in Global Risk (MIRI)
- Basic AI drives
- Racing to the Precipice: a Model of Artificial Intelligence Development
- The Ethics of Artificial Intelligence
- The Superintelligent Will: Motivation and Instrumental Rationality in Advanced Artificial Agents
- Wireheading in mortal universal agents
- AGI Safety Literature Review
Research Collections
- Bruce Schneier – Resources on Existential Risk, p. 110
- Aligning Superintelligence with Human Interests: A Technical Research Agenda (MIRI)
- MIRI publications
- Stanford One Hundred Year Study on Artificial Intelligence (AI100)
- Preparing for the Future of Intelligence: White House report that discusses the current state of AI and future applications, as well as recommendations for the government’s role in supporting AI development.
- Artificial Intelligence, Automation, and the Economy: White House report that discusses AI’s potential impact on jobs and the economy, and strategies for increasing the benefits of this transition.
- IEEE Special Report: Artificial Intelligence: Report that explains deep learning, in which neural networks teach themselves and make decisions on their own.
Case Studies
- The Asilomar Conference: A Case Study in Risk Mitigation (Katja Grace, MIRI)
- Pre-Competitive Collaboration in Pharma Industry (Eric Gastfriend and Bryan Lee, FLI): A case study of pre-competitive collaboration on safety in industry.
Blog posts and talks
- AI control
- AI Impacts
- No time like the present for AI safety work
- AI Risk and Opportunity: A Strategic Analysis
- Where We’re At – Progress of AI and Related Technologies: An introduction to the progress of research institutions developing new AI technologies.
- AI safety
- Wait But Why on Artificial Intelligence
- Response to Wait But Why by Luke Muehlhauser
- Slate Star Codex on why AI-risk research is not that controversial
- Less Wrong: A toy model of the AI control problem
- What Should the Average EA Do About AI Alignment?
- Waking Up Podcast #116 – AI: Racing Toward the Brink with Eliezer Yudkowsky
Books
- Superintelligence: Paths, Dangers, Strategies
- Life 3.0: Being Human in the Age of Artificial Intelligence
- Our Final Invention: Artificial Intelligence and the End of the Human Era
- Facing the Intelligence Explosion
- E-book about the AI risk (including a “Terminator” scenario that’s more plausible than the movie version)
Organizations
- Machine Intelligence Research Institute: A non-profit organization whose mission is to ensure that the creation of smarter-than-human intelligence has a positive impact.
- Centre for the Study of Existential Risk (CSER): A multidisciplinary research center dedicated to the study and mitigation of risks that could lead to human extinction.
- Future of Humanity Institute: A multidisciplinary research institute bringing the tools of mathematics, philosophy, and science to bear on big-picture questions about humanity and its prospects.
- Partnership on AI: Established to study and formulate best practices on AI technologies, to advance the public’s understanding of AI, and to serve as an open platform for discussion and engagement about AI and its influences on people and society.
- Global Catastrophic Risk Institute: A think tank leading research, education, and professional networking on global catastrophic risk.
- Organizations Focusing on Existential Risks: A brief introduction to some of the organizations working on existential risks.
- 80,000 Hours: A career guide for AI safety researchers.
Many of the organizations listed on this page and their descriptions are from a list compiled by the Global Catastrophic Risk institute; we are most grateful for the efforts that they have put into compiling it. These organizations above all work on computer technology issues, though many cover other topics as well. This list is undoubtedly incomplete; please contact us to suggest additions or corrections.
About the Future of Life Institute
The Future of Life Institute (FLI) is the world’s oldest and largest AI think tank, with a team of 35+ full-time staff operating across the US and Europe. FLI has been working to steer the development of transformative technologies towards benefitting life and away from extreme large-scale risks since its founding in 2014. Find out more about our mission or explore our work.
Related content

The Pro-Human AI Declaration

Governor DeSantis Directs Florida State Agencies to Partner with Future of Life Institute to Shield Families from AI Harm

Statement from Max Tegmark on the Department of War’s ultimatum
