Deep Safety: NIPS 2017 Report

Contents
This year’s NIPS gave me a general sense that near-term AI safety is now mainstream and long-term safety is slowly going mainstream. On the near-term side, I particularly enjoyed Kate Crawford’s keynote on neglected problems in AI fairness, the ML security workshops, and the Interpretable ML symposium debate that addressed the “do we even need interpretability?” question in a somewhat sloppy but entertaining way. There was a lot of great content on the long-term side, including several oral / spotlight presentations and the Aligned AI workshop.
Value alignment papers
Inverse Reward Design (Hadfield-Menell et al) defines the problem of an RL agent inferring a human’s true reward function based on the proxy reward function designed by the human. This is different from inverse reinforcement learning, where the agent infers the reward function from human behavior. The paper proposes a method for IRD that models uncertainty about the true reward, assuming that the human chose a proxy reward that leads to the correct behavior in the training environment. For example, if a test environment unexpectedly includes lava, the agent assumes that a lava-avoiding reward function is as likely as a lava-indifferent or lava-seeking reward function, since they lead to the same behavior in the training environment. The agent then follows a risk-averse policy with respect to its uncertainty about the reward function.
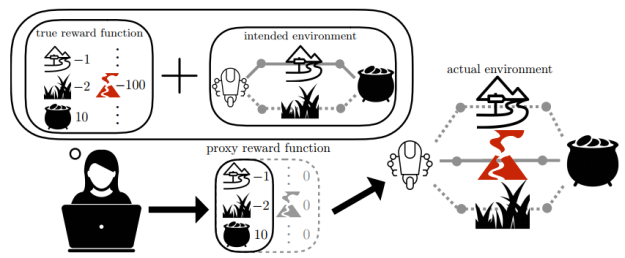
The paper shows some encouraging results on toy environments for avoiding some types of side effects and reward hacking behavior, though it’s unclear how well they will generalize to more complex settings. For example, the approach to reward hacking relies on noticing disagreements between different sensors / features that agreed in the training environment, which might be much harder to pick up on in a complex environment. The method is also at risk of being overly risk-averse and avoiding anything new, whether it be lava or gold, so it would be great to see some approaches for safe exploration in this setting.
Repeated Inverse RL (Amin et al) defines the problem of inferring intrinsic human preferences that incorporate safety criteria and are invariant across many tasks. The reward function for each task is a combination of the task-invariant intrinsic reward (unobserved by the agent) and a task-specific reward (observed by the agent). This multi-task setup helps address the identifiability problem in IRL, where different reward functions could produce the same behavior.
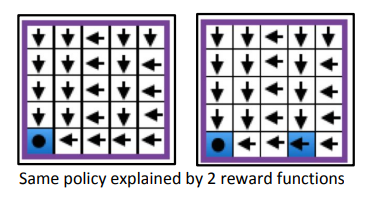
The authors propose an algorithm for inferring the intrinsic reward while minimizing the number of mistakes made by the agent. They prove an upper bound on the number of mistakes for the “active learning” case where the agent gets to choose the tasks, and show that a certain number of mistakes is inevitable when the agent cannot choose the tasks (there is no upper bound in that case). Thus, letting the agent choose the tasks that it’s trained on seems like a good idea, though it might also result in a selection of tasks that is less interpretable to humans.
Deep RL from Human Preferences (Christiano et al) uses human feedback to teach deep RL agents about complex objectives that humans can evaluate but might not be able to demonstrate (e.g. a backflip). The human is shown two trajectory snippets of the agent’s behavior and selects which one more closely matches the objective. This method makes very efficient use of limited human feedback, scaling much better than previous methods and enabling the agent to learn much more complex objectives (as shown in MuJoCo and Atari).

Dynamic Safe Interruptibility for Decentralized Multi-Agent RL (El Mhamdi et al) generalizes the safe interruptibility problem to the multi-agent setting. Non-interruptible dynamics can arise in a group of agents even if each agent individually is indifferent to interruptions. This can happen if Agent B is affected by interruptions of Agent A and is thus incentivized to prevent A from being interrupted (e.g. if the agents are self-driving cars and A is in front of B on the road). The multi-agent definition focuses on preserving the system dynamics in the presence of interruptions, rather than on converging to an optimal policy, which is difficult to guarantee in a multi-agent setting.
Aligned AI workshop
This was a more long-term-focused version of the Reliable ML in the Wild workshop held in previous years. There were many great talks and posters there – my favorite talks were Ian Goodfellow’s “Adversarial Robustness for Aligned AI” and Gillian Hadfield’s “Incomplete Contracting and AI Alignment”.
Ian made the case of ML security being important for long-term AI safety. The effectiveness of adversarial examples is problematic not only from the near-term perspective of current ML systems (such as self-driving cars) being fooled by bad actors. It’s also bad news from the long-term perspective of aligning the values of an advanced agent, which could inadvertently seek out adversarial examples for its reward function due to Goodhart’s law. Relying on the agent’s uncertainty about the environment or human preferences is not sufficient to ensure safety, since adversarial examples can cause the agent to have arbitrarily high confidence in the wrong answer.

Gillian approached AI safety from an economics perspective, drawing parallels between specifying objectives for artificial agents and designing contracts for humans. The same issues that make contracts incomplete (the designer’s inability to consider all relevant contingencies or precisely specify the variables involved, and incentives for the parties to game the system) lead to side effects and reward hacking for artificial agents.

The central question of the talk was how we can use insights from incomplete contracting theory to better understand and systematically solve specification problems in AI safety, which is a really interesting research direction. The objective specification problem seems even harder to me than the incomplete contract problem, since the contract design process relies on some level of shared common sense between the humans involved, which artificial agents do not currently possess.
Interpretability for AI safety
I gave a talk at the Interpretable ML symposium on connections between interpretability and long-term safety, which explored what forms of interpretability could help make progress on safety problems (slides, video). Understanding our systems better can help ensure that safe behavior generalizes to new situations, and it can help identify causes of unsafe behavior when it does occur.
For example, if we want to build an agent that’s indifferent to being switched off, it would be helpful to see whether the agent has representations that correspond to an off-switch, and whether they are used in its decisions. Side effects and safe exploration problems would benefit from identifying representations that correspond to irreversible states (like “broken” or “stuck”). While existing work on examining the representations of neural networks focuses on visualizations, safety-relevant concepts are often difficult to visualize.
Local interpretability techniques that explain specific predictions or decisions are also useful for safety. We could examine whether features that are idiosyncratic to the training environment or indicate proximity to dangerous states influence the agent’s decisions. If the agent can produce a natural language explanation of its actions, how does it explain problematic behavior like reward hacking or going out of its way to disable the off-switch?
There are many ways in which interpretability can be useful for safety. Somewhat less obvious is what safety can do for interpretability: serving as grounding for interpretability questions. As exemplified by the final debate of the symposium, there is an ongoing conversation in the ML community trying to pin down the fuzzy idea of interpretability – what is it, do we even need it, what kind of understanding is useful, etc. I think it’s important to keep in mind that our desire for interpretability is to some extent motivated by our systems being fallible – understanding our AI systems would be less important if they were 100% robust and made no mistakes. From the safety perspective, we can define interpretability as the kind of understanding that help us ensure the safety of our systems.
For those interested in applying the interpretability hammer to the safety nail, or working on other long-term safety questions, FLI has recently announced a new grant program. Now is a great time for the AI field to think deeply about value alignment. As Pieter Abbeel said at the end of his keynote, “Once you build really good AI contraptions, how do you make sure they align their value system with our value system? Because at some point, they might be smarter than us, and it might be important that they actually care about what we care about.”
(Thanks to Janos Kramar for his feedback on this post, and to everyone at DeepMind who gave feedback on the interpretability talk.)
This article was originally posted here.
About the Future of Life Institute
The Future of Life Institute (FLI) is a global non-profit with a team of 20+ full-time staff operating across the US and Europe. FLI has been working to steer the development of transformative technologies towards benefitting life and away from extreme large-scale risks since its founding in 2014. Find out more about our mission or explore our work.
Related content
Other posts about AI, Recent News

The Pause Letter: One year later

Catastrophic AI Scenarios
Gradual AI Disempowerment
